
A First Look at Google’s N-Gram Corpus
In this post we will focus on the problem of finding the appropriate word boundaries in strings like “homebuiltairplanes”, as is common in web URLs like www.homebuiltairplanes.com. This is an interesting problem because humans do it so easily, but there is no obvious programmatic solution. We will begin this article by addressing the complexity of this problem, continue by implementing a simple model using a subset of Google’s n-gram corpus, and finish by describing our future plans to enhance the model. As usual, all of the code and data used in this post is available from this blog’s Github page.
Word Segmentation
We just claimed word segmentation is a hard problem, but in fact the segmentation part is quite easy! We’ll give a quick overview of the segmentation algorithm which assumes that we can evaluate a segmentation for optimality.
First, we note that by an elementary combinatorial argument there are $ 2^{n-1}$ segmentations of a word with $ n$ letters. To see this, imagine writing a segmentation of “homebuiltairplanes” with vertical bars separating the letters, as in “home | built | ai | rpla | nes”. The maximum number of vertical bars we could place is one less than the number of letters, and every segmentation can be represented by describing which of the $ n-1$ gaps contain vertical bars and which do not. We can hence count up all segmentations by counting up the number of ways to place the bars. A computer scientist should immediately recognize that these “bars” can represent digits in a binary number, and hence all binary numbers with $ n-1$ digits correspond to valid segmentations, and these range from 0 to $ 2^{n-1} – 1$, giving $ 2^{n-1}$ total numbers.
One can also prove this by fixing the number $ k$ of segments the word is broken into and counting all the segmentations for each $ k$. We leave it as an exercise to the reader.
The key fact to glean from that counting problem is that enumerating all possible segmentations is unfeasible. The right way to approach this problem is to mimic a human’s analysis. This will result in a dynamic program, and readers who have followed along will recognize the approach from our post on the Levenshtein metric. In addition we have a Python primer which doubles as a primer on dynamic programming.
A human who looks at the word “homebuiltairplanes” performs a mental scanning of the word. First we check if “h” is a good word, and then move to “ho”, “hom”, and finally decide “home” is likely the right word. From there we split the word into “home” and “builtairplanes”, and segment the remainder appropriately. In addition, one does not consider any of the segmentations whose first word is “h”, and neither one which begins with “homebu,” and the reason is that these are not words (nor are they likely to mean anything even if they aren’t words; we will discuss this nuance soon). Hence, all of the $ 2^{15}$ segmentations that make the first word “h” can be disregarded, as can the $ 2^{11}$ whose first word is “homebu”.
However, following these directions too strictly (and programs are quite strict in following directions) will get us into a number of traps. The mathematical mind will come up with many examples for which this reasoning is ambiguous or flat-out faulty. Here are two such suspects. The first is “lovesnails”. If we prematurely pick the first word as “love”, then we will be forced to choose the segmentation “love snails”, when it might truly be “loves nails”. Regardless of which segmentation is more likely, we simply need to consider them both in whatever judgement system we come up with. The second example is “bbcamerica”, as in www.bbcamerica.com. In particular, if we expect to find dictionary words in our segmentation, we’ll be quite disappointed, because no word begins with “bb”. Our solution then is to break free of the dictionary, and to allow potentially odd segmentations, being confident that our criterion for judging segmentation optimality will successfully discard the bad ones.
Before we liberate ourselves from the confines of Oxford’s vocabulary, let’s implement the procedure that performs the segmentation, abstracting out the optimality criterion. We note that (as usual with a dynamic program) we will need to memoize our recursion, and one should refer to our post on the Levenshtein metric and the Python primer on dynamic programming for an explanation of the “@memoize” decorator.
First, we implement the “splitPairs” function, which accepts a string $ s$ as input and returns a list containing all possible split pairs $ (u,v)$ where $ s = uv$. We achieve this by a simple list comprehension (gotta love list comprehensions!) combined with string slicing.
def splitPairs(word):
return [(word[:i+1], word[i+1:]) for i in range(len(word))]
Indeed, “word[a:b]” computes a substring of “word” including the indices from $ a$ to $ b-1$, where blank entries for $ a$ and $ b$ denote the beginning and end of the string, respectively. For example, on the input string “hello”, this function computes:
>>> splitPairs("hello")
[('h', 'ello'), ('he', 'llo'), ('hel', 'lo'),
('hell', 'o'), ('hello', '')]
Note that the last entry in this list is crucial, because we may not want to segment the input word at all, and in the following we assume that “splitPairs” returns all of our possible choices of action. Next we define the “segment” function, which computes the optimal segmentation of a given word. In particular, we assume there is a global function called “wordSeqFitness” which reliably computes the fitness of a given sequence of words, with respect to whether or not it’s probably the correct segmentation.
def segment(word):
if not word: return []
allSegmentations = [[first] + segment(rest)
for (first, rest) in splitPairs(word)]
return max(allSegmentations, key = wordSeqFitness)
In particular, we are working by induction on the length of a word. Assuming we know the optimal segmentations for all substrings not including the first letter, we can construct the best segmentation which includes the first letter. The first line is the base case (there is only one choice for the empty string), and the second line is the meat of the computation. Here, we look at all possible split pairs, including the one which considers the entire word as a good segmentation, and we find the maximum of those segmentations with respect to “wordSeqFitness”. By induction we know that “segment” returns the optimal segmentation on every call, since each “rest” variable contains a strictly smaller substring which does not include the first letter. Hence, we have covered all possible segmentations, and the algorithm is correct.
Again, note how simple this algorithm was. Call it Python’s syntactic sugar if you will, but the entire segmentation was a mere four lines of logic. In other words, the majority of our work will be in figuring out exactly how to judge the fitness of a segmented word. For that, we turn to Google.
Google’s N-Gram Corpus
The biggest obstacle in “word segmentation” turns out to be identifying what words are, or rather what strings are most likely to have meaning. If we stick to a naive definition of what a word is, i.e., anything found in the Oxford English Dictionary, we end up with a very weak program. It wouldn’t be able to tell that “bbc” should be a word, as in our above example, and further it wouldn’t be able to tell which words are more likely than others (the OED has some pretty obscure words in it, but no mention of which are more common).
The solution here is to create a probabilistic model of the English language. Enter Google. To date Google has provided two major data corpora: the first, released in 2006, contains the frequency counts of language data from over a trillion words from a random sample of the entire internet. They gathered all n-grams, sequences of $ n$ tokens (a “token” was defined arbitrarily by the researchers at Google), and reported the counts of those which occurred above a certain threshold. Unfortunately this corpus is over a hundred gigabytes of uncompressed data (24GB compressed), and consequently it can’t be found online (you have to order it on 6 DVDs from UPenn instead).
The second corpus is more specifically limited to language data from scanned books. Again organized as n-grams, this data set has some advantages and disadvantages. In particular, it was scanned directly from books, so optical character recognition was used to determine what image segments correspond to words, and what words they are. Due to deterioration or printing errors in the scanned books (for older years, these cover all books printed), this results in a lot of misinterpreted tokens. On the other hand, all of these sources are proofread for mistakes. Considering the banality of the web, we can probably assume this corpus has a higher data quality. Furthermore, tokens that appear commonly on the web (abbreviations like “lol” and “LotR” come to mind) are unlikely to occur in a book. For better or worse, if we use the book data set, we probably won’t have an easy time segmenting words which use such terms.
In the future we plan to obtain and process through the book data set (unless we can find the web data set somewhere…), but for now we use a convenient alternative. A researcher and Stanford professor Peter Norvig modified and released a subset of Google’s web corpus. He made all of the entries case insensitive, and he removed any tokens not consisting entirely of alphabet letters. Our first investigation will use his 1-gram file, which contains the 333,333 most commonly used single words. Perhaps unsurprisingly, this covers more than 98% of all 1-grams found, and the entire corpus easily fits into memory at a mere 5MB. Even better, we will design our program so that it works with data in any form, so the data sets can be swapped out at will.
Each line in Norvig’s data file has the form $ word \left \langle tab \right \rangle n$. The first few lines are:
the 23135851162
of 13151942776
and 12997637966
to 12136980858
a 9081174698
in 8469404971
for 5933321709
is 4705743816
on 3750423199
that 3400031103
by 3350048871
this 3228469771
with 3183110675
i 3086225277
you 2996181025
While the last few are (quite uselessly):
goolld 12711
goolh 12711
goolgee 12711
googook 12711
googllr 12711
googlal 12711
googgoo 12711
googgol 12711
goofel 12711
gooek 12711
gooddg 12711
gooblle 12711
gollgo 12711
golgw 12711
The important aspect here is that the words have associated counts, and we can use them to probabilistically compare the fitness of two segmentations of a given word. In particular, we need to define a probabilistic model that evaluates the likelihood of a given sequence of words being drawn from a theoretical distribution of all sequences of words.
Naive Bayes, the Reckless Teenager of Probability Models
The simplest useful model we could create is one in which we simply take the probability of each word in the segmentation and multiply them together. This is Bayes’s Rule, with the added assumption that each event (the occurrence of a word) is independent of the others. In common parlance, this is the equivalent to saying that the probability of a sequence of words occurring is the probability that the first word occurs (anywhere in the sequence) AND the second word occurs AND the third word occurs, and so on. Obviously the independence assumption is very strong. For a good counterexample, the sequence “united states of america” is far more common than the sequence “states america of united”, even though in this model they have the same probability.
The simplicity of this model makes it easy to implement, and hence it comes up often in applications, and so it has a special name: naive Bayes. In essence, a piece of data has a number of features (here, the features are the words in the sequence), and we make the assumption that the features occur independently of one another. The idea has been applied to a cornucopia of classification problems, but it usually serves a stepping stone to more advanced models which don’t ignore the underlying structure of the data. It can also be an indicator of whether more advanced models are really needed, or a measure of problem complexity.
For word segmentation, however, it’s a sensible simplification. Indeed, it is quite unlikely that a sequence of words will show up in a different order (as the complexity of the words in the segmentation increases, it’s probably downright impossible), so our “united states of america” example doesn’t concern us. On the other hand, we still have the example “lovesnails”, which the naive Bayes model might not sensibly handle. For a more contrived example, consider the segmentations of “endear”. Clearly “end” and “ear” are common words, but they are very rarely written in that order. Much more common is the single word “endear”, and an optimal model would take this into account, as well as three, four, and five-word sequences in our segmentation.
For a general model not pertaining just to segmentation, we’d truly love it if we could take into account $ n$-grams for any $ n$, because indeed some (very long) texts include words which have high probability of being placed together, but are far apart. Take, for instance, a text about sports in the UK. It is quite unlikely to see the word “soccer”, and more likely to see the word “wimbledon,” if the word United Kingdom shows up anywhere in the text (or, say, words like “Manchester”). There are some models which try to account for this (for instance, see the work on the “sequence memoizer” done at Columbia). However, here we expect relatively few tokens, so once we get there, we can limit our concerns to 5-grams at most. And, as most mathematicians and programmers agree, the best solution is often the simplest one.
Implementation
Our naive Bayes probability model will end up being a class in Python. Upon instantiating the class, we will read in the data file, organize the word counts, and construct a way to estimate the probability of a word occurring, given our smaller data set.
In particular, our class will inherit the functionality of a dictionary. The relevant line is
class OneGramDist(dict):
This allows us to treat any instance of the class as if it were a dictionary. We can further override the different methods of a dictionary, extending the functionality in any way we wish, but for this application we won’t need to do that.
The relevant methods we need to implement are an initialization, which reads the data in, and a “call” method (the method called when one treats the object as a function; this will be clear from the examples that follow), which returns the probability of a given word.
def __init__(self):
self.gramCount = 0
for line in open('one-grams.txt'):
(word, count) = line[:-1].split('\t')
self[word] = int(count)
self.gramCount += self[word]
def __call__(self, word):
if word in self:
return float(self[word]) / self.gramCount
else:
return 1.0 / self.gramCount
In the init function, we take each line in the “one-grams.txt” file, which has the form discussed above, and extract the word and count from it. We then store this data into the “self” object (which, remember, is also a dictionary), and then tally up all of the counts in the variable “gramCount”. In the call function, we simply return the number of times the word was counted, divided by the total “gramCount”. If a word has not been seen before, we assume it has a count of 1, and return the appropriate probability. We also note that this decision will come back to bite us soon, and we will need to enhance our model to give a better guess on unknown probabilities.
To plug this in to our segmentation code from earlier, we instantiate the distribution and implement “wordSeqFitness()” as follows:
singleWordProb = OneGramDist()
def wordSeqFitness(words):
return functools.reduce(lambda x,y: x+y,
(math.log10(singleWordProb(w)) for w in words))
First, this requires us to import both the “math” and “functools” libraries. The “reduce” function is the same as the “fold” function (see our primer on Racket and functional programming), and it combines a list according to a given function. Here the function is an anonymous function, and the syntax is
lambda arg1, arg2, ..., argN: expression
Here our lambda is simply adding two numbers. The list we give simply computes the probabilities of each word, and takes their logarithms. This actually does compute what we want to compute, but in logarithmic coordinates. In other words, we use the simple observation that $ \log(ab) = \log(a) + \log(b)$. The reason for this is that each single word probability is on the order of $ 10^{-10}$, and so taking a product of around forty words will give a probability of near $ 10^{-400}$, which is smaller than the smallest floating point number Python allows. Python would report a probability of zero for such a product. In order to remedy this, we use this logarithm trick, and we leave it as an exercise to the reader to compute how ridiculously small the numbers we can represent in this coordinate system are.
Drawbacks, and Improvements
Now let us see how this model fares with a few easy inputs.
$ python -i segment.py
>>> segment("hellothere")
['hello', 'there']
So far so good.
>>> segment("himynameisjeremy")
['himynameisjeremy']
What gives?! Let’s fiddle with this a bit:
>>> segment("hi")
['hi']
>>> segment("himy")
['hi', 'my']
>>> segment("himyname")
['hi', 'my', 'name']
>>> segment("himynameis")
['himynameis']
>>> wordSeqFitness(['himynameis'])
-11.76946906492656
>>> wordSeqFitness(['hi', 'my', 'name', 'is'])
-11.88328049583244
There we have it. Even though we recognize that the four words above are common, their combined probability is lower than the probability of a single long word! In fact, this is likely to happen for any long string. To fix this, we need to incorporate information about the frequency of words based on their length. In particular, assume we have an unknown word $ w$. It is unlikely to be a word if it’s longer than, say, ten characters long. There are some well-known distributions describing the frequency of actual words by their length, and it roughly fits the curve:
$$f = aL^bc^L; a = 0.16, b = 2.33, c = 0.5$$Unfortunately this doesn’t help us. We want to know among all strings of a given length what proportion of them are words. With that, we can better model the probability of an unseen word actually being a word.
Luckily, we aren’t helpless nontechnical lambs. We are programmers! And we have a huge dictionary of words from Google’s n-gram corpus sitting right here! A quick python script (after loading in the dictionary using our existing code above) gives us the necessary numbers:
>>> for i in range(1,15):
... words = [x for x in singleWordProb if len(x) == i]
... print(len(words)/(26.0 ** i))
...
1.0
1.0
0.738336367774
0.0681436224222
0.00336097435179
0.000158748771704
6.23981380309e-06
2.13339205291e-07
6.52858936946e-09
1.84887277585e-10
4.6420710809e-12
1.11224101901e-13
2.54478475236e-15
5.68594239398e-17
Looking at the exponents, we see it’s roughly exponential with a base of $ 1/10$ for each length after 2, and we verify this by looking at a log plot in Mathematica:
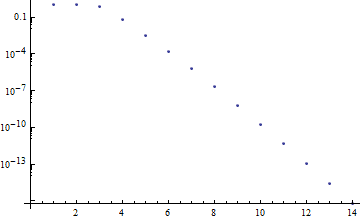
The linearity of the picture tells us quite immediately that it’s exponential. And so we update the unknown word probability estimation as follows:
def __call__(self, word):
if word in self:
return float(self[word]) / self.gramCount
else:
return 1.0 / (self.gramCount * 10**(len(key) - 2))
And indeed, our model now fares much better:
>>> segment("homebuiltairplanes")
['homebuilt', 'airplanes']
>>> segment("bbcamerica")
['bbc', 'america']
>>> segment("nevermind")
['nevermind']
>>> segment("icanhascheezburger")
['i', 'can', 'has', 'cheez', 'burger']
>>> segment("lmaorofllolwtfpwned")
['lmao', 'rofl', 'lol', 'wtf', 'pwned']
>>> segment("wheninthecourseofhumanevents")
['when', 'in', 'the', 'course', 'of', 'human', 'events']
>>> segment("themostmercifulthingintheworldithinkistheinabilityofthehumanmindtocorrelateallitscontentsweliveonaplacidislandofignoranceinthemidstofblackseasofinfinityanditwasnotmeantthatweshouldvoyagefar")
['the', 'most', 'merciful', 'thing', 'in', 'the', 'world', 'i', 'think', 'is', 'the', 'inability', 'of', 'the', 'human', 'mind', 'to', 'correlate', 'all', 'its', 'contents', 'we', 'live', 'on', 'a', 'placid', 'island', 'of', 'ignorance', 'in', 'the', 'midst', 'of', 'black', 'seas', 'of', 'infinity', 'and', 'it', 'was', 'not', 'meant', 'that', 'we', 'should', 'voyage', 'far']
>>> s = 'Diffusepanbronchiolitisdpbisaninflammatorylungdiseaseofunknowncauseitisasevereprogressiveformofbronchiolitisaninflammatoryconditionofthebronchiolessmallairpassagesinthelungsthetermdiffusesignifiesthat'
>>> segment(s)
['diffuse', 'pan', 'bronchiolitis', 'dpb', 'is', 'an', 'inflammatory', 'lung', 'disease', 'of', 'unknown', 'cause', 'it', 'is', 'a', 'severe', 'progressive', 'form', 'of', 'bronchiolitis', 'an', 'inflammatory', 'condition', 'of', 'the', 'bronchioles', 'small', 'air', 'passages', 'in', 'the', 'lungs', 'the', 'term', 'diffuse', 'signifies', 'that']
Brilliant! The last bit is from the wikipedia page on diffuse panbronchiolitis, and it only mistakes the “pan” part of the admittedly obscure technical term. However, we are much more impressed by how our model embraces internet slang :). We can further verify intended behavior by deliberately misspelling a long word to see how the model fares:
>>> segment("antidisestablishmentarianism")
['antidisestablishmentarianism']
>>> segment("antidisestablishmentarianasm")
['anti', 'disestablishment', 'ariana', 'sm']
That second segmentation is certainly more likely than the original misspelled word (well, if we assume that no words are misspelled before segmentation).
Perhaps the most beautiful thing here is that this entire program is independent of the data used. If we wanted to instead write a program to segment, say, German words, all we’d need is a data file with the German counts (which Google also provides with its book corpus, along with Russian, Chinese, French, Spanish, and Hebrew). So we’ve written a much more useful program than we originally intended. Now compare this to the idea of a program which hard codes rules for a particular language, which was common practice until the 1980’s. Of course, it’s obvious now how ugly that method is, but apparently it’s still sometimes used to augment statistical methods for language-specific tasks.
Of course, we still have one flaw: the data is sloppy. For instance, the segmentation of “helloworld” is just “helloworld.” It turns out that this token appears on the internet in various forms, and commonly enough to outweigh the product of “hello” and “world” alone. Unfortunately, we can’t fix this by fiddling with the data we already have. Instead, we would need to extend the model to look at frequency counts of sequences of words (here, sequences of length 2). Google provides sequence counts of up to length 5, but they quickly grow far too large to fit in memory. One possible solution, which we postpone for a future post, would be to set up a database containing all 1-gram and 2-gram data, and therein bypass the need to store a big dictionary in memory. Indeed, then we could avoid truncating the 1-gram data as we did in this post.
The Next Steps
Next time, we will look at another application of our truncated corpus: cryptanalysis. In particular, we will make an effort to break substitution ciphers via a local search method. In the not so near future, we also plan to investigate some other aspects of information representation. One idea which seems promising is to model a document as a point in some high dimensional space (perhaps each dimension corresponds to a count of a particular 1-gram), and then use our familiar friends from geometry to compare document similarity, filter through information, and determining the topic of a document via clustering. The idea is called the vector space model for information retrieval. In addition, we can use the corpus along with our friendly Levenshtein metric to implement a spell-checker. Finally, we could try searching for phonetically similar words using a Levenshteinish metric on letter $ n$-grams (perhaps $ n$ is between 2 and 4).
Until next time!
P.S., in this model, “love snails” is chosen as the best segmentation over “loves nails.” Oh the interpretations…
Want to respond? Send me an email, post a webmention, or find me elsewhere on the internet.