Here’s a simple puzzle with a neat story. A rich old woman is drafting her will and wants to distribute her expansive estate equally amongst her five children. But her children are very greedy, and the woman knows that if he leaves her will unprotected her children will resort to nefarious measures to try to get more than their fair share. In one fearful scenario, she worries that the older four children will team up to bully the youngest child entirely out of his claim! She desperately wants them to cooperate, so she decides to lock the will away, and the key is a secret integer $ N$. The question is, how can she distribute this secret number to her children so that the only way they can open the safe is if they are all present and willing?

estate
A mathematical way to say this is: how can she distribute some information to her children so that, given all of their separate pieces of information, they can reconstruct the key, but for every choice of fewer than 5 children, there is no way to reliably recover the key? This is called the secret sharing problem. More generally, say we have an integer $ N$ called the secret, a number of participants $ k$, and a number required for reconstruction $ r$. Then a secret sharing protocol is the data of a method for distributing information and a method for reconstructing the secret. The distributing method is an algorithm $ D$ that accepts as input $ N, k, r$ and produces as output a list of $ k$ numbers $ D(N, k) = (x_1, x_2, \dots, x_k)$. These are the numbers distributed to the $ k$ participants. Then the reconstruction method is a function $ R$ which accepts as input $ r$ numbers $ (y_1, \dots, y_r)$ and outputs a number $ M$. We want two properties to hold :
- The reconstruction function $ R$ outputs $ N$ when given any $ r$ of the numbers output by $ D$.
- One cannot reliably reconstruct $ N$ with fewer than $ r$ of the numbers output by $ D$.
The question is: does an efficient secret sharing protocol exist for every possible choice of $ r \leq k$? In fact it does, and the one we’ll describe in this post is far more secure than the word “reliable” suggests. It will be so hard as to be mathematically impossible to reconstruct the secret from fewer than the desired number of pieces. Independently discovered by Adi Shamir in 1979, the protocol we’ll see in this post is wonderfully simple, and as we describe it we’ll build up a program to implement it. This time we’ll work in the Haskell programming language, and you can download the program from this blog’s Github page. And finally, a shout out to my friend Karishma Chadha who worked together with me on this post. She knows Haskell a lot better than I do.
Polynomial Interpolation
The key to the secret sharing protocol is a beautiful fact about polynomials. Specifically, if you give me $ k+1$ points in the plane with distinct $ x$ values, then there is a unique degree $ k$ polynomial that passes through the points. Just as importantly (and as a byproduct of this fact), there are infinitely many degree $ k+1$ polynomials that pass through the same points. For example, if I give you the points $ (1,2), (2,4), (-2,2)$, the only quadratic (degree 2) polynomial that passes through all of them is $ 1 + \frac{1}{2}x + \frac{1}{2} x^2$.
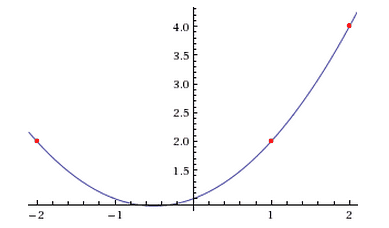
An example of an interpolating polynomial of degree 2.
The proof that you can always find such a polynomial is pretty painless, so let’s take it slowly and write a program as we go. Suppose you give me some list of $ k+1$ points $ (x_0, y_0), \dots, (x_k, y_k)$ and no two $ x$ values are the same. The proof has two parts. First we have to prove existence, that some degree $ k$ polynomial passes through the points, and then we have to prove that the polynomial is unique. The uniqueness part is easier, so let’s do the existence part first. Let’s start with just one point $ (x_0, y_0)$. What’s a degree zero polynomial that passes through it? Just the constant function $ f(x) = y_0$. For two points $ (x_0, y_0), (x_1, y_1)$ it’s similarly easy, since we all probably remember from basic geometry that there’s a unique line passing through any two points. But let’s write the line in a slightly different way:
$$\displaystyle f(x) = \frac{(x-x_1)}{x_0-x_1}y_0 + \frac{(x-x_0)}{x_1-x_0} y_1$$Why write it this way? Because now it should be obvious that the polynomial passes through our two points: if I plug in $ x_0$ then the second term is zero and the first term is just $ y_0(x_0 – x_1) / (x_0 – x_1) = y_0$, and likewise for $ x_1$.
For example, if we’re given $ (1, 3), (2, 5)$ we get:
$$\displaystyle f(x) = \frac{(x – 2)}{(1-2)} \cdot 3 + \frac{(x-1)}{(2-1)} \cdot 5 $$Plugging in $ x = 1$ cancels the second term out, leaving $ f(1) = \frac{1-2}{1-2} \cdot 3 = 3$, and plugging in $ x = 2$ cancels the first term, leaving $ f(2) = \frac{(2-1)}{(2-1)} \cdot 5 = 5$.
Now the hard step is generalizing this to three points. But the suggestive form above gives us a hint on how to continue.
$$\displaystyle f(x) = \frac{(x-x_1)(x-x_2)}{(x_0-x_1)(x_0-x_2)}y_0+\frac{(x-x_0)(x-x_2)}{(x_1-x_0)(x_1-x_2)}y_1+ \frac{(x-x_0)(x-x_1)}{(x_2-x_0)(x_2-x_1)}y_2$$Notice that the numerators of the terms take on the form $ y_j \prod_{i \ne j} (x-x_i)$, that is, a product $ (x-x_0)(x-x_1), \dots, (x-x_n) y_j$ excluding $ (x – x_j)$. Thus, all terms will cancel out to 0 if we plug in $ x_i$, except one term, which has the form
$$\displaystyle y_i \cdot \frac{\prod_{j \neq i} (x-x_j)}{\prod_{j \neq i} (x_i – x_j)}$$Here, the fraction on the right side of the term cancels out to 1 when $ x_i$ is plugged in, leaving only $ y_i$, the desired result. Now that we’ve written the terms in this general product form, we can easily construct examples for any number of points. We just do a sum of terms that look like this, one for each $ y$ value. Try writing this out as a summation, if you feel comfortable with notation.
Let’s go further and write an algorithm to construct the polynomial for us. Some preliminaries: we encode a polynomial as a list of coefficients in degree-increasing order, so that $ 1 + 3x + 5x^3$ is represented by [1,3,0,5].
type Point = (Rational, Rational)
type Polynomial = [Rational] --Polynomials are represented in ascending degree order
Then we can write some simple functions for adding and multiplying polynomials
addPoly :: Polynomial -> Polynomial -> Polynomial
addPoly [] [] = []
addPoly [] xs = xs
addPoly xs [] = xs
addPoly (x:xs) (y:ys) = (x+y) : (addPoly xs ys)
multNShift :: Polynomial -> (Rational, Int) -> Polynomial
multNShift xs (y, shift) =
(replicate shift 0) ++ ( map ((*) y) xs)
multPoly :: Polynomial -> Polynomial -> Polynomial
multPoly [] [] = []
multPoly [] _ = []
multPoly _ [] = []
multPoly xs ys = foldr addPoly [] $ map (multNShift ys) $ zip xs [0..]
In short, multNShift multiplies a polynomial by a monomial (like $ 3x^2 (1 + 7x + 2x^4)$), and multPoly does the usual distribution of terms, using multNShift to do most of the hard work. Then to construct the polynomial we need one more helper function to extract all elements of a list except a specific entry:
allBut :: Integer -> [a] -> [a]
allBut i list = snd $ unzip $ filter (\ (index,_) -> i /= index) $ zip [0..] list
And now we can construct a polynomial from a list of points in the same way we did mathematically.
findPolynomial :: [Point] -> Polynomial
findPolynomial points =
let term (i, (xi,yi)) =
let prodTerms = map (\ (xj, _) -> [-xj/(xi - xj), 1/(xi - xj)]) $ allBut i points
in multPoly [yi] $ foldl multPoly [1] prodTerms
in foldl addPoly [] $ map term $ zip [0..] points
Here the sub-function term constructs the $ i$-th term of the polynomial, and the remaining expression adds up all the terms. Remember that due to our choice of representation the awkward 1 sitting in the formula signifies the presence of $ x$. And that’s it! An example of it’s use to construct $ 3x – 1$:
*Main> findPolynomial [(1,2), (2,5)]
[(-1) % 1,3 % 1]
Now the last thing we need to do is show that the polynomial we constructed in this way is unique. Here’s a proof.
Suppose there are two degree $ n$ polynomials $ f(x)$ and $ g(x)$ that pass through the $ n+1$ given data points $ (x_0, y_0), (x_1, y_1), \dots , (x_n, y_n)$. Let $ h(x) = p(x) – q(x)$, and we want to show that $ h(x)$ is the zero polynomial. This proves that $ f(x)$ is unique because the only assumptions we made at the beginning were that $ f,g$ both passed through the given points. Now since both $ f$ and $ g$ are degree $ n$ polynomials, $ h$ is a polynomial of degree at most $ n$. It is also true that $ h(x_i) = p(x_i) – q(x_i) = y_i – y_i = 0$ where $ 0\leq i\leq n$. Thus, we have (at least) $ n+1$ roots of this degree $ n$ polynomial. But this can’t happen by the fundamental theorem of algebra! In more detail: if a nonzero degree $ \leq n$ polynomial really could have $ n+1$ distinct roots, then you could factor it into at least $ n+1$ linear terms like $ h(x) = (x – x_0)(x – x_1) \dots (x – x_n)$. But since there are $ n+1$ copies of $ x$, $ h$ would need to be a degree $ n+1$ polynomial! The only way to resolve this contradiction is if $ h$ is actually the zero polynomial, and thus $ h(x) = f(x) – g(x) = 0$, $ f(x) = g(x)$.
This completes the proof. Now that we know these polynomials exist and are unique, it makes sense to give them a name. So for a given set of $ k+1$ points, call the unique degree $ k$ polynomial that passes through them the interpolating polynomial for those points.
Secret Sharing with Interpolating Polynomials
Once you think to use interpolating polynomials, the connection to secret sharing seems almost obvious. If you want to distribute a secret to $ k$ people so that $ r$ of them can reconstruct it here’s what you do:
- Pick a random polynomial $ p$ of degree $ r-1$ so that the secret is $ p(0)$.
- Distribute the points $ (1, p(1)), (2, p(2)), \dots, (k, p(k))$.
Then the reconstruction function is: take the points provided by at least $ r$ participants, use them to reconstruct $ p$, and output $ p(0)$. That’s it! Step 1 might seem hard at first, but you can just notice that $ p(0)$ is equivalent to the constant term of the polynomial, so you can pick $ r-1$ random numbers for the other coefficients of $ p$ and output them. In Haskell,
makePolynomial :: Rational -> Int -> StdGen -> Polynomial
makePolynomial secret r generator =
secret : map toRational (take (r-1) $ randomRs (1, (numerator(2*secret))) generator)
share :: Rational -> Integer -> Int -> IO [Point]
share secret k r = do
generator <- getStdGen
let poly = makePolynomial secret r generator
ys = map (eval poly) $ map toRational [1..k]
return $ zip [1..] ys
In words, we initialize the Haskell standard generator (which wraps the results inside an IO monad), then we construct a polynomial by letting the first coefficient be the secret and choosing random coefficients for the rest. And findPolynomial is the reconstruction function.
Finally, just to flush the program out a little more, we write a function that encodes or decodes a string as an integer.
encode :: String -> Integer
encode str = let nums = zip [0..] $ map (toInteger . ord) str
integers = map (\(i, n) -> shift n (i*8)) nums
in foldl (+) 0 integers
decode :: Integer -> String
decode 0 = ""
decode num = if num < 0
then error "Can't decode a negative number"
else chr (fromInteger (num .&. 127)) : (decode $ shift num (-8))
And then we have a function that shows the whole process in action.
example msg k r =
let secret = toRational $ encode msg
in do points (numerator x, numerator y)) points
let subset = take r points
encodedSecret = eval (findPolynomial subset) 0
putStrLn $ show $ numerator encodedSecret
putStrLn $ decode $ numerator encodedSecret
And a function call:
*Main> example "Hello world!" 10 5
10334410032606748633331426632
[(1,34613972928232668944107982702),(2,142596447049264820443250256658),(3,406048862884360219576198642966),(4,916237517700482382735379150124),(5,1783927975542901326260203400662),(6,3139385067235193566437068631142),(7,5132372890379242119499357692158),(8,7932154809355236501627439048336),(9,11727493455321672728948666778334),(10,16726650726215353317537380574842)]
10334410032606748633331426632
Hello world!
Security
The final question to really close this problem with a nice solution is, “How secure is this protocol?” That is, if you didn’t know the secret but you had $ r-1$ numbers, could you find a way to recover the secret, oh, say, 0.01% of the time?
Pleasingly, the answer is a solid no. This protocol has something way stronger, what’s called information-theoretic security. In layman’s terms, this means it cannot possibly be broken, period. That is, without taking advantage of some aspect of the random number generator, which we assume is a secure random number generator. But with that assumption the security proof is trivial. Here it goes.
Pick a number $ M$ that isn’t the secret $ N$. It’s any number you want. And say you only have $ r-1$ of the correct numbers $ y_1, \dots, y_{r-1}$. Then there is a final number $ y_r$ so that the protocol reconstructs $ M$ instead of $ N$. This is no matter which of the unused $ x$-values you pick, no matter what $ M$ and $ r-1$ numbers you started with. This is simply because adding in $ (0, M)$ defines a new polynomial $ q$, and you can use any point on $ q$ as your $ r$-th number.
Here’s what this means. A person trying to break the secret sharing protocol would have no way to tell if they did it correctly! If the secret is a message, then a bad reconstruction could produce any message. In information theory terms, knowing $ r-1$ of the numbers provides no information about the actual message. In our story from the beginning of the post, no matter how much computing power one of the greedy children may have, the only algorithm they have to open the safe is to try every combination. The mother could make the combination have length in the millions of digits, or even better, the mother could encode the will as an integer and distribute that as the secret. I imagine there are some authenticity issues there, since one could claim to have reconstructed a false will, signatures and all, but there appear to be measures to account for this.
One might wonder if this is the only known secret sharing protocol, and the answer is no. Essentially, any time you have an existence and uniqueness theorem in mathematics, and the objects you’re working with are efficiently constructible, then you have the potential for a secret sharing protocol. There are two more on Wikipedia. But people don’t really care to find new ones anymore because the known protocols are as good as it gets.
On a broader level, the existence of efficient secret sharing protocols is an important fact used in the field of secure multiparty computation. Here the goal is for a group of individuals to compute a function depending on secret information from all of them, without revealing their secret information to anyone. A classic example of this is to compute the average of seven salaries without revealing any of the salaries. This was a puzzle featured on Car Talk, and it has a cute answer. See if you can figure it out.
Until next time!
Want to respond? Send me an email, post a webmention, or find me elsewhere on the internet.