We’re ironically searching for counterexamples to the Riemann Hypothesis.
- Setting up Pytest
- Adding a Database
- Search Strategies
- Unbounded integers
- Deploying with Docker
- Performance Profiling
- Scaling up
In the last article we rearchitected the application so that we could run as many search instances as we want in parallel, and speed up the application by throwing more compute resources at the problem.
This is good, but comes with a cost. The complexity of this new architecture requires us to manage many different containers and AWS instances. Let’s take a step back. In this article, we’ll focus on improving the “production worthiness” of the application. In particular, we will:
- Automate running tests on every pull request
- Add some extra error handling code
- Clean up stale blocks when worker jobs fail
- Automate checking Python type hints and test coverage
- Add static analysis checks
- Add alerting to tell us when jobs fail
- Automate the process of updating the application with new code
Automating test running
The main benefit of writing tests is that you can run them. It’s even better when the tests are run automatically on a pull request. It guards buggy changes from breaking the main code branch.
There are many systems that work with GitHub to automate running tests. For this project I used CircleCI, which has a nice free tier. “CI” stands for continuous integration, which is an idea that if you guard your main branch well enough, you can ensure that the main branch is always in a state that can be released or deployed to production servers. And if this is the case, then you might as well have the computer manage regular releases for you (provided all tests pass).
Since we don’t yet have a way to automate releases, we’ll start by running tests on every pull request. This pull request was my first failed attempt and configuring CircleCI based on their tutorial, and this commit fixed it (which was really 15 attempts squashed into one commit post hoc). Originally I thought I could use CircleCI’s built in python testing jobs, but since this project requires a compiled component—the gmp library for unbounded integer arithmetic, and the associated Postgres extension—we need to manually install some other packages. Thankfully, CircleCI uses containers, so the configuration looks a lot like a Dockerfile. Unfortunately, CircleCI’s containers use a different Ubuntu operating system for their base image, which means the packages I had to install have different names than I expected.
So after an hour or two of trial and error, now it works. When you open a new pull request you see the tests run.

And when the tests are finished and passing you see green (otherwise red).

I must admit, most of these tools (see Coveralls below) are primarily designed for Python projects without compiled components. The defaults all tend to fail and you fall back to running arbitrary shell scripts. That’s one good reason to get familiar with standard linux package managers.
Better error handling
A few times the block processing job ran into some errors, and the container died. I don’t have a means to alert when the jobs fail, so I manually checked on them every once in a while. One error was an overflow error as described in this issue. While I might want to dig in a bit more to solve that problem, the effect was that the job died and the block was left in the IN_PROGRESS state. I want errors to result in marking the block as failed, engaging the retry loop, to exercise the possibility that the issue is somehow transient or specific to one broken worker job.
It’s relatively simple, and this pull request does the trick. This commit is the main part.
I added a nice test that demonstrates (again) the benefit of having interfaces. To test this behavior, we need to inject a fake error into the search_strategy.process_block function. One way to do that is to use mocks, and “monkey patch” the process_block method to operate differently during that test. In my opinion, this is bad design, because those tests can quickly become stale, and monkey patching results in odd behavior when you don’t set up the patch just right. Instead, writing a test-specific implementation of the search strategy interface is a safer approach. This commit does that.
Once that was working, I turned to the overflow error, which I fixed in this pull request. Turns out, the integers involved in the computation are so large that their logarithms don’t fit in a single floating point number. So I had to switch to using the log function from the gmp library, which outputs a multi-precision floating point number.
Handle stale blocks
Due to the jobs failing in the previous section, and as an extra safety measure against further failures—including when a job is killed in order to relaunch it with new code—I decided to add an extra job devoted to looking for stale blocks (which have been in_progress for more than an hour) and marking them as failed. This issue describes the idea. Once deployed, the current production system will automatically patch up its past failures. If only it were so easy for we humans. This pull request adds the new job, a new Dockerfile, and an end-to-end test. I deployed the job on the same server as the generator job, since both jobs spend most of their time sleeping.
Type checker tests
So far in the project, I’ve been adding type hints to most of the functions. Type hints are optional in Python, but if you use them, you can add an automated test to ensure that your code matches what the type hints say. This helps you have more confidence that your code is correct. There’s a lot more to say on this subject (software engineers often argue about the value of type checking), but I’ll refrain from providing my opinion for now, assume it’s worthwhile, and show what it’s like to use it.
For this project I’ll use mypy. Since I haven’t been running a type checker on this project yet, I expect the first run will find a lot of errors. When I run mypy riemann/*.py it reports 29 errors. Notably, these two errors suggest problems with our dependencies.
riemann/superabundant.py:6: error: Cannot find implementation or library stub for module named 'gmpy2'
riemann/superabundant.py:7: error: Cannot find implementation or library stub for module named 'numba'
The problem here is that if a dependency doesn’t use type hints, then the type checker won’t know what to do with functions from the dependent module. The options are to create a “stub” for those types, or to tell the type checker to ignore them. Stubbing is supposed to be easy, but for project that have compiled dependencies it can be considerably harder. For now I went with ignoring missing stubs. This pull request does the extra work to run the type checker in the automated test suite, and fix some minor type errors (one of which spotted a real bug).
Test Coverage
Test coverage (or “code coverage”) tools report which lines of your program are exercised by some test. Like type hints, requiring test coverage has advantages and disadvantages. Briefly, I feel code coverage is a good baseline understanding of what’s tested, but coverage does not imply adequate testing, nor does lack of coverage imply poor testing. Rather, it’s a rough guide that can show you glaring holes in what you thought to write tests for. There’s more to say, but not today.
Pytest has plugins for coverage measuring, and when you install them you can just run pytest --cov --cov-report html:cov_html to generate html pages that show line-by-line and file-by-file coverage stats. Mine looked like this.
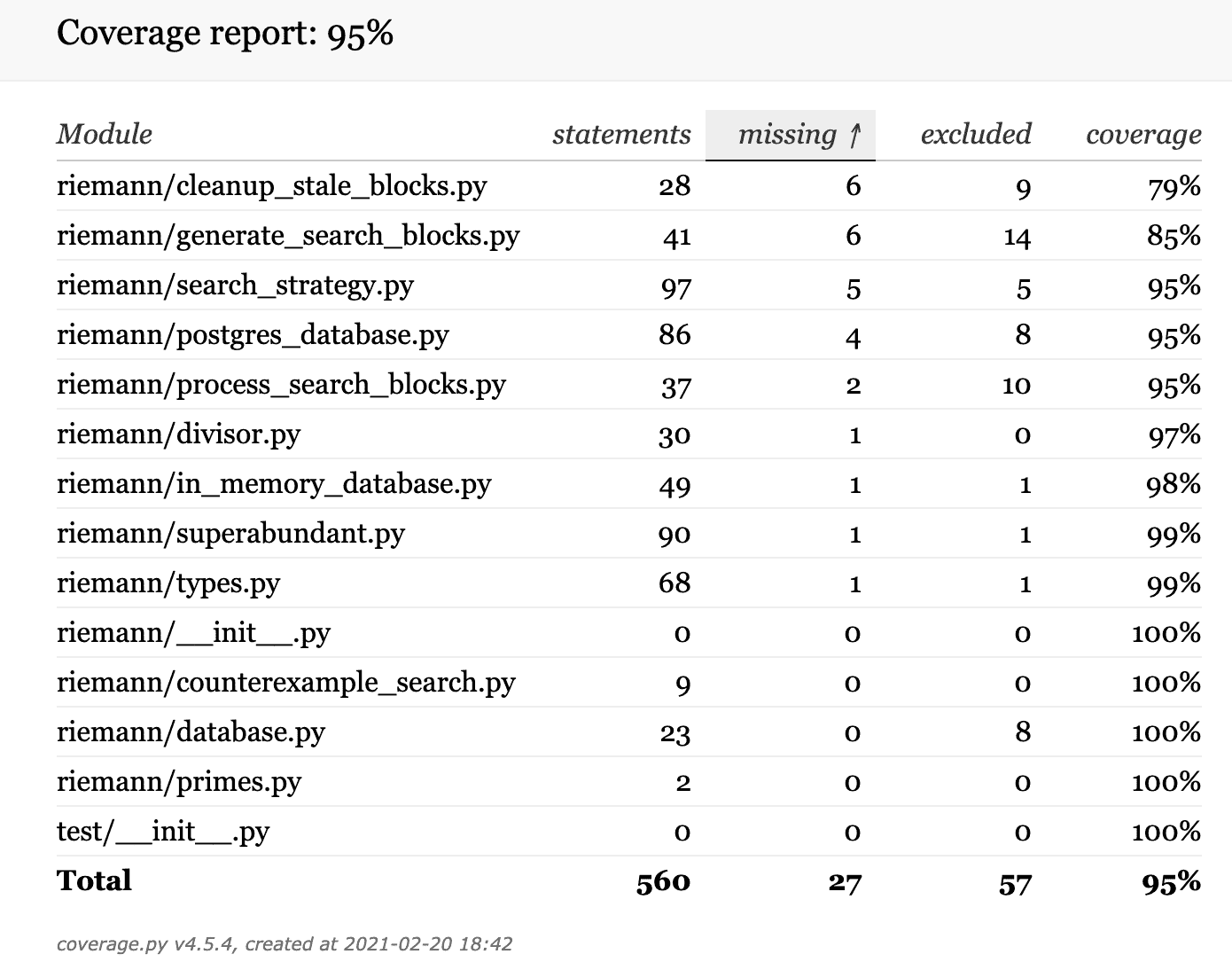
This project’s coverage report (after fixing up issues described below)
A few obstacles, again coming from the fact that the project has compiled parts. In particular, Numba does not provide coverage support yet. So to get coverage statistics, you have to disable the jit compiler during the test execution. This simply requires setting the environment variable NUMBA_DISABLE_JIT=1. Disabling this made some of the tests run extremely slowly, but some minor changes restored a reasonable runtime (2 minutes, mostly end-to-end tests).
The other problem was the end to end tests. You need to add a special hook to allow the Python coverage tool to see the lines of code executed by subprocesses, which is used heavily by the end to end tests. This pull request shows the steps to overcoming both of these problems.
Also in that pull request is the configuration of Coveralls. This allows code coverage to be computed during the continuous integration test run, and shown on the pull request before merging, with the option to “fail” the code coverage test if the changes in the pull request reduce code coverage too much.
The configuration together between CircleCI and Coveralls required setting the Coveralls project token as an environment variable during CircleCI workflows, and running coveralls after the pytest command finished. Now pull requests look like this.
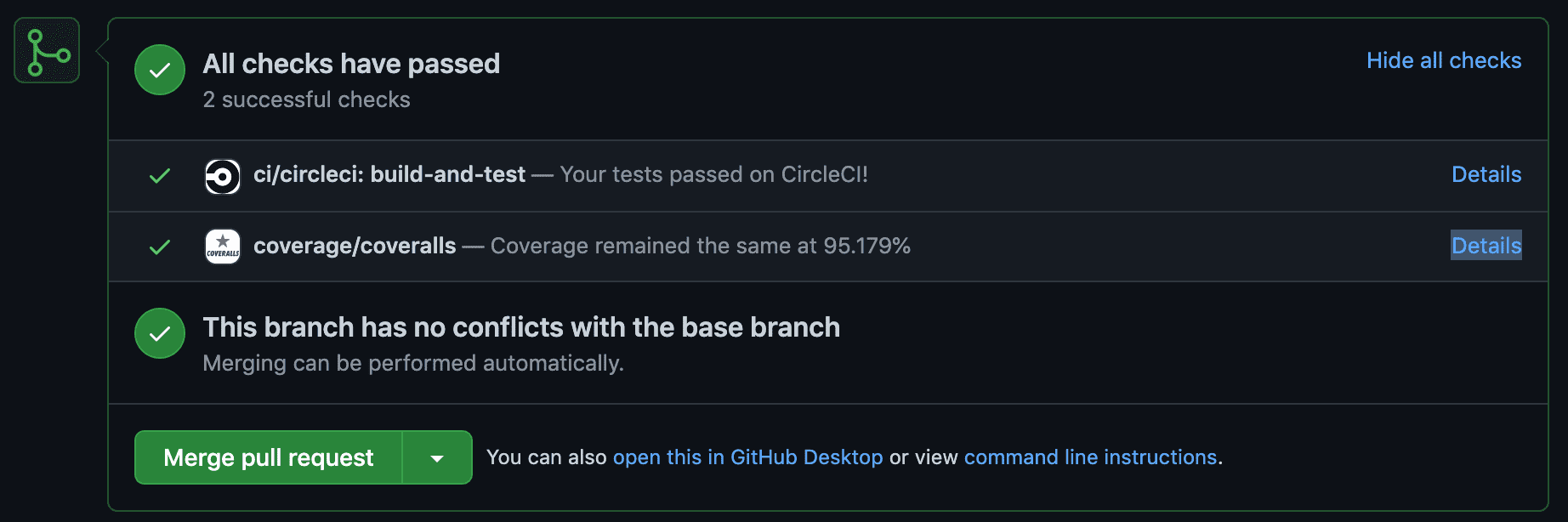
Now Pull Requests show a coverage report and warn if the coverage percentage is too low.
Static Analysis
Static analysis refers to tools that look at your code and point out problems or suggest improvements. In Python there are scant few good static analysis tools, in part because Python is designed to be very dynamic. It’s not possible for an automated system to be 100% sure what a piece of code does, because even importing a module can do weird things like change the behavior of arithmetic operations. Static analysis plummets in value as false positives increase, but being conservative in making recommendations also limits the value.
Static analysis also refers to the ability to do autocomplete, or reformatting source code to match a particular style, as well as type checking. But I just want to focus on semantic code improvements, not “prettifying” code. A simple example is dead code, which is unused by the application and can be safely deleted. Another is SQL injection vulnerabilities.
For this project I will configure lgtm.com, which is a nice general-purpose static analysis framework that hooks into any GitHub repository without configuration and supports a few important languages. Here is an example run, which resulted in 11 alerts like this one
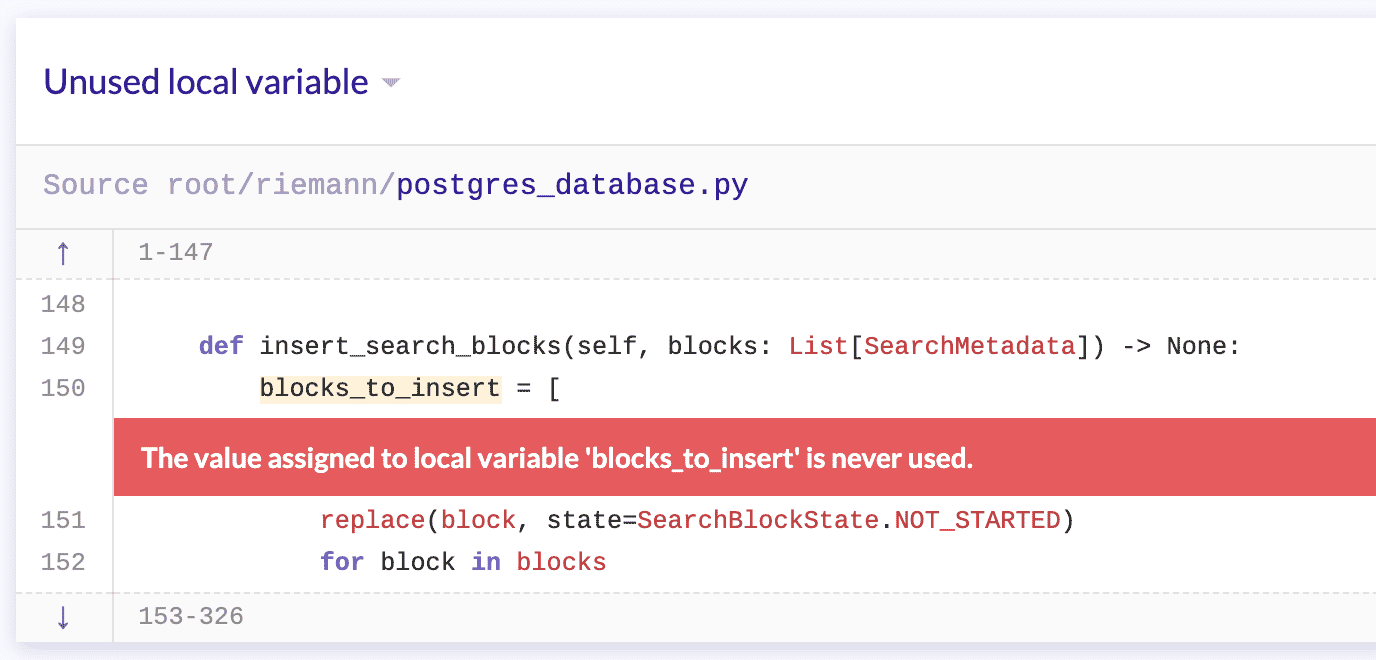
An example alert found by LGTM
And it’s right! I didn’t need that entire statement because the variable it defined was unused. This one was low-stakes, but another alert pointed to a more serious and subtle bug, related to how the SuperabundantSearchStrategy class mutates its internal state. I can clean that up later, but for now let’s marvel at how the static analysis tool caught the bug with no work on my part. Fantastic!
This pull request addresses the 11 alerts generated by LGTM, most of which are unused imports. LGTM is even nice enough to post comments showing the improvements by PR.
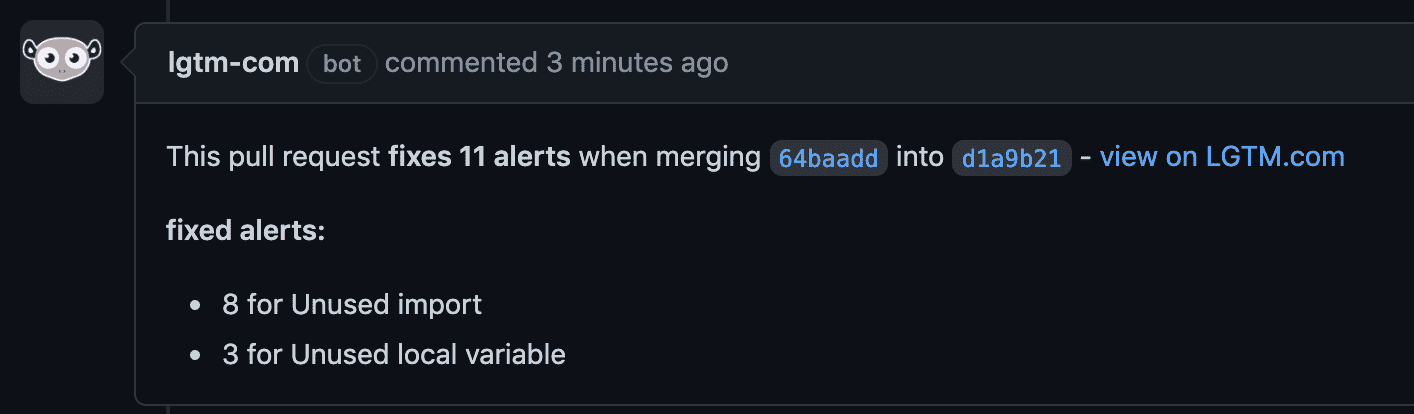
The nice comment left by LGTM when merging a PR that fixes alerts.
Badges
A little bit of flair: I added badges to the project README, so I could show off the fact that tests are passing and I have decent code coverage and code that passes static analysis checks.

Alerting on job failure
Next, I wanted to set up some rudimentary alerting so that I can know when my docker containers fail. If I don’t have this, I have to manually check up on them, and if they fail and I forget, I end up paying money to run the servers for nothing.
There are many approaches to do monitoring and alerting, many software packages, and many opinions. This series is supposed to show you the ideas and problems that software engineers care about, but not go overboard so that we still have time to do math. So I’ll implement what I consider the simplest solution, describe what it lacks, and briefly mention some other approaches.
We need two components: the ability to tell if a container has failed, and the ability to send an email. The former is easy, because the docker runtime provides a pleasant CLI.
docker ps -a --format="{{.Image}}" --filter="status=exited"
docker ps -a shows the status of all running containers, the --filter flag makes the command show only the containers that have exited, and the --format flag makes the command print a restricted subset of the information, in this case just the image name. This makes it suitable for providing as input to a program, since there is no special text added to the output just for human-readability.
The second part, sending an email, is more complicated because popular email services like Gmail have stringent rules. In short, Gmail blocks email from any unknown sender by default (because spam), and so in order to send an email successfully from a program, you need to jump through a bunch of hoops to authenticate the system to send on behalf of an account with a popular provider. You cant just use sendmail. Since I use Gmail, we’ll use it for authentication.
To authenticate a program to send from a Gmail account, you have to generate an “app password” for your Google account, and then configure the mail sender program to use it. The program I chose is the CLI ssmtp, and you can configure it to use your Google account and password via a configuration file typically stored at /etc/ssmtp/ssmtp.conf. The configuration file looks like this (with sensitive data censored with x’s)
root=xxxx@gmail.com
mailhub=smtp.gmail.com:465
FromLineOverride=YES
AuthUser=xxxx@gmail.com
AuthPass=xxxxxxxxxxxxx
TLS_CA_FILE=/etc/ssl/certs/ca-certificates.crt
UseTLS=Yes
rewriteDomain=gmail.com
hostname=xx.xx.xx.xx.xx
Once you have this, you can send email using a command-line invocation like
echo "Email message body goes here" | ssmtp recipient@gmail.com
However, this poses another small problem. While we could manually configure each of these config files on each of our servers, we would like to automate it eventually (next section), and automating it would seem to require us to store the sensitive information in a script that goes into our version-controlled (public!) code repository.
To deal with this, we need a simple way to manage secrets. The typical way to do this is via unix environment variables. In short, environment variables are variables and values you can store in the execution context of any script or terminal session. The most common example is $PATH, which stores a list of directories to search for programs in when you run a program. E.g., if you run docker ps, it will look to see if there’s a program called docker in /user/bin/, and if not try /usr/local/bin/, and so on until exhausting all entries in $PATH. We used environment variables to pass the postgres host ip to our docker containers, but it can also be used for passing secrets to programs to avoid storing passwords in text files that might become public accidentally.
You can set an environment variable using export VARIABLE="any value here". All values are strings. In our case, we will define two environment variables GMAIL_APP_USER—for the email address of the Google account to authenticate as—and GMAIL_APP_PASS for the app password. Then this bash script (run with sudo -E to ensure environment variables are passed from the calling context) will set up the configuration in one go, and this python script will orchestrate the loop of checking docker ps -a and sending an email if it sees any failed containers, passing the password via an environment variable as well. An improvement I discovered later allows us to also avoid storing the password in the ssmtp configuration file, and instead pass it directly from the environment to the python script.
Note this uses the python-dotenv library to easily import environment variables stored in a .env file. We must be careful not to check the .env file into version control, so we update the .gitignore and add an .env.template as a hint to show what environment variables are needed in .env.
Finally, though the deploy script is not quite useful as a standalone script (the docker containers live on different machines), it’s still useful to remind us how to manually deploy. So after exporting the right environment variables we have a few simple new steps to follow to run the monitoring script.
sudo apt install -y python3-pip ssmtp
pip3 install -r alerts/requirements.txt
sudo -E alerts/configure_ssmtp.sh
nohup python3 -m alerts.monitor_docker &
The last line may be new. nohup tells the operating system to “disconnect” the program from the shell that launched it (it’s actually a bit more specific, but has this effect), and the & has the program run in the background. This effectively allows us to launch the monitoring job in an ssh session, and then close the ssh session without terminating the program.
That raises an interesting point: how can we be sure that the monitoring program doesn’t fail? Who watches the watcher? For us, nobody. There is always more engineering you can do if you want a higher level of safety and security, but for us the returns diminish quickly. Eventually we will check the program manually and notice if it broke.
Automating deployment
The final step of our “productionization” process will be to set up some mechanism to deploy our application when we make updates. Like monitoring and alerting, there are quite a few frameworks out there. The main one for us to consider is called a container orchestration system, and the biggest one for Docker is called Kubernetes. If you read through the Kubernetes homepage, you’ll see all kinds of benefits that align with what we want: automatic deployment and container management, including monitoring, restarting jobs, and changing compute resource limits like RAM limit and CPU. These are all things which have taken up our time while building this project! AWS has support for Kubernetes, as well as their own homegrown solutions.
The difficulty around these topics is that you can spend as much (or more) of your time learning the details of the framework than you would making a functional-but-suboptimal version yourself. Such frameworks can also extra layers of frustration because of the additional jargon and learning curve, the mess of configuration, and the tendency for corporate products to change and force you to change in turn. Docker was already a decent investment, it’s asking a lot to invest more!
If I had all the time in the world, I’d go with Kubernetes. But in the next article I want to get back to doing some math and visualization with the data we’ve collected. So let’s pretend we can’t use a framework, and write a basic script that will automate our deployment for us. That is, the script will ssh into the EC2 instances that run each piece of the application, run git pull on each, run docker stop on the containers and remove them, build new container images from the new code, launch those images, and do it all in the right dependency order. The approach won’t be super resilient or have all the engineering ribbons and bows, but in the worst case we can manually fix any problems.
This script does just that. It’s simple enough for starters, and didn’t take me more than an hour to get working. We’ll leave Kubernetes for future work.
That said, in the process of building and testing the deployment script I hit a disappointing problem: docker was deleting the database when I removed the container. Or rather, it started over and I couldn’t find where the data was stored on the host machine. This appears to be because I was letting the Postgres base Dockerfile define a “volume,” which wasn’t saved when I removed the built Docker image (docker prune). So I read up about docker volumes and created a named volume and attached it to the docker container at startup time. The volume won’t disappear when the container stops now, and I can automatically back up the volume (coming soon), so that further blunders don’t result in losing all the data again.
Next time we’ll get back to the mathematical aspects and look for patterns in the data we’ve found so far. I, for one, am optimistic we’ll find the secrets we need to disprove RH.
Want to respond? Send me an email, post a webmention, or find me elsewhere on the internet.