Decidability Versus Efficiency
In the early days of computing theory, the important questions were primarily about decidability. What sorts of problems are beyond the power of a Turing machine to solve? As we saw in our last primer on Turing machines, the halting problem is such an example: it can never be solved a finite amount of time by a Turing machine. However, more recently (in the past half-century) the focus of computing theory has shifted away from possibility in favor of determining feasibility. In particular, we want to know how fast we can solve a particular problem on a Turing machine. The goal is to design efficient algorithms for important real-world problems, and know when it is impossible to design a more efficient algorithm than what we already have. From a mathematical perspective, that often means we would like to find the boundary problems: those which are “just barely” too hard to admit an efficient algorithm. Of course, this requires us to first define what it means for an algorithm to be “efficient.”
These questions are intimately intertwined with big-O analysis, which we presented in our very first primer on this blog, and the definitions we investigate in the sequel require fluency in such notation. That being said, we try to give colloquial analogues to the most important ideas.
The Class P
The general goal here is to describe classes of problems that roughly correspond to how efficiently one can solve them. The first such class (and by all rights, the smallest class we will consider) is called P, which stands for “polynomial.”
Definition: P is the set of languages which can be decided by a Turing machine in $ O(n^k)$ for some $ k$, where $ n$ is the input size of the problem. In the common notation:
$$\displaystyle \textup{P} = \bigcup_{k \in \mathbb{N}} \textup{TIME}(n^k)$$Where $ \textup{TIME}(n^k)$ is the set of problems decidable in $ O(n^k)$ time. Recall that a language is any set of strings (any subset of $ \Sigma^*$, as we have been investigating in our past computing theory primers and our post about metrics on words).
We don’t have too much to say about P itself, except that many common problems are in P. The real difficulty is in proving that some problem does not lie in P.
Here is an example this author has used to explain to elementary school children what’s it’s like to not be in P. Consider a deck of 52 playing cards, and your goal is to sort the cards by suit and then by rank (as it is when you open a fresh pack of cards). There is one obvious way to do this that children teach themselves quite readily: just look for the Ace of spades, put it on the bottom of a new stack. Then find the two of spades, and continue in this manner until the deck is sorted. This algorithm takes $ O(n^2)$, since in the very worst case the deck is sorted in reverse order, and if you’re too dim to realize it, you look through the entire deck at every step.
Of course, there are much faster ways to do it than the approach we detailed above, and it is a well-known theorem that sorting is $ \Theta(n \log(n))$. That is, there is both a lower bound and an upper bound of $ n \log(n)$ for the general sorting problem.
Now let’s investigate a ridiculous algorithm for sorting cards. What if at each step, we shuffled the deck, and then checked to see if it magically became sorted due to our shuffling. Forgetting for a moment that randomness comes into play, we would find the correct sorting once in $ 52!$ trials, and it would take 52 steps to check if it was sorted. For a deck of $ n$ cards, this would hence take time $ O(n! \cdot n)$, which would take so long even for 52 cards, that the sun would go out before you could finish. But what if we didn’t know a better way?
For an example of a problem where we don’t know a better way, consider the problem of graph coloring. Is there a Turing machine which, when given as input a graph $ G$ and a number $ k$, can determine in polynomial time whether $ G$ admits a $ k$-coloring? There is an obvious algorithm to decide the problem: there are only finitely many choices of assignments of vertices to colors, and we can simply check them all. In fact, there are $ k^n$ of them, where $ n$ is the number of vertices of $ G$.
Unfortunately, this algorithm is not polynomial in runtime: we would have to enumerate all of the different colorings, and check whether each is a valid coloring; this process is easily seen to be $ o(nk^n)$, which is far from polynomial for arbitrary $ k > 2$.
But the true challenge is this: how do we know there is no “faster” algorithm? Of all the crazy wild ideas one could have to solve a problem, how do we know none can be so clever that they reduce the running time to be a polynomial in $ n$?
In fact, we don’t know for sure that there isn’t! This is the heart of the open problem which is succinctly called “P vs. NP”.
The Class NP
While P is a class of “easy” problems from one perspective (problems that can be solved quickly, even in the worst case), being a member of NP is another measure of “easiness,” but from a different perspective.
Definition: NP is the class of problems which have a polynomial-time verifier. That is, given an input $ w$ to a problem $ A \in \textup{NP}$, there is a string $ c$ called a certificate and a Turing machine $ M$ for which $ M$ verifies that $ c$ proves $ w \in A$ and runs in polynomial time.
This definition is a bit hard to swallow, but examples clarify the situation greatly. For the problem of graph coloring, we note that a certificate would simply be a list of pairs $ (v_i, n_i)$ which give a coloring of the graph $ G$. It is quite trivial to define a polynomial-time Turing machine that ensures the coloring of $ G$ is valid. Hence, graph coloring is in NP. This is the case with most problems in NP: a proof that $ w \in A$ is hard to find, but easy to verify once you have it.
There is another definition of NP which is often useful, and it gives a reason for prefixing the “polynomial” part of P with an N.
Definition: NP is the set of problems which are solvable by a nondeterministic Turing machine in polynomial time.
For the motivating picture behind “nondeterministic Turing machines,” we turn to an analogy. Imagine you have an infinite number of computers running in parallel, and they can communicate instantaneously. What sorts of problems could we solve in polynomial time with such a machine? We could certainly solve graph coloring: simply have each machine try one of the $ k^n$ different colorings, and have the entire machine halt when one coloring is found (or when they all finish, we can safely reject that the graph is k-colorable).
So we can reformulate the definition in set notation as:
$$\displaystyle \textup{NP} = \bigcup_{k \in \mathbb{N}} \textup{NTIME}(n^k)$$Here $ \textup{NTIME}(f(n))$ is the set of all languages which can be solved in time $ f(n)$ on a nondeterministic Turing machine.
In other words, “NP” stands for “nondeterministic polynomial-time” problems. And in fact this definition is equivalent to existence of a polynomial-time verifier, as in our first definition. To see this, note that we can construct a nondeterministic machine that enumerates all possible certificates (lending to our analogy, one on each of the infinitely numerous parallel computers), and then tests them using the polynomial-time verifier. Since each branch uses a polynomial-time algorithm, the whole Turing machine runs in (nondeterministic) polynomial time. On the other hand, if some branch of computation halts in deterministic time, then the sequence of configurations of the tape for that branch has polynomial length, and so a Turing machine can simply run that computation to ensure it follows the rules of Turing machines and ends in an accepting state. This clearly represents a certificate.
One might ask why we care about infinitely parallel computers. In reality, we can only have finitely many computations going at once, so why bother with this silly mathematical uselessness? As it often turns out in mathematics, it is useful to think about such structures simply because they capture the essence of what we wish to study in a concise and formal manner. For complexity theory, nondeterministic Turing machines capture the level of complexity we wish to understand: in a sense, it’s the “next level up” from polynomial-time decidable problems.
K-Clique and 3-Sat
We have two more examples of problems in NP which will be important later in this post: the problems of 3-Satisfiability and finding a k-Clique.
Definition: Let $ \varphi(x_1, \dots, x_n)$ be a propositional formula in $ n$ boolean variables. $ \varphi$ is satisfiable if there exists an assignment of the variables $ x_1, \dots, x_n \to \left \{ \textup{T}, \textup{F} \right \}$ that makes $ \varphi$ true.
For example, we could have the formula
$$\displaystyle (x \vee y \vee \overline{z}) \wedge (\overline{x} \vee \overline{y} \vee z)$$And this is satisfiable by the assignment of $ x = \textup{T}, y = \textup{F}, z = \textup{T}$.
It should be obvious to the reader now that determining whether a formula is satisfiable is in NP: a certificate is just a list of variables mapping to true or false, and checking that the formula is satisfied by a given assignment can be done in polynomial time.
In 3-Satisfiability (usually shortened to 3-Sat), we simply restrict the form of $ \varphi$ and ask the same question. The form is called conjunctive normal form, and colloquially it is a bunch of clauses joined with “and,” where each clause is a bunch of variables (and their negations) connected by “or”. Moreover, the “3” in 3-Sat requires that each clause contain exactly three literals. For example, the equation given above would be a valid input to 3-Sat.
k-Clique, on the other hand, is a question about graphs. Given a graph $ G$ and a positive integer $ k$, determine whether $ G$ contains a complete subgraph of $ k$ vertices. (In a complete graph, there is an edge connecting each pair of vertices; the name “clique” is motivated by the party problem, in the sense that there is a “clique” of friends at the party who are all mutually friends with each other.)
As expected, a certificate that a graph has a $ k$-Clique is just a list of the vertices in the clique, and checking that all pairs of vertices listed have a connecting edge is easily seen to take $ O(|G|k^2) = O(n^3)$, which is polynomial in the size of the input.
NP-Completeness
As it turns out, the problems of 3-Satisfiability and k-Clique are quite special (as is graph coloring). They belong to a special sub-class of NP called NP-complete. Before we can define what NP-complete means, we have to be able to compare problems in NP.
Definition: Given two languages $ A, B$, we say $ A \leq_p B$, or $ A$ is polynomial-time reducible to $ B$ if there exists a computable function $ f: \Sigma^* \to \Sigma^*$ such that $ w \in A$ if and only if $ f(w) \in B$, and $ f$ can be computed in polynomial time.
We have seen this same sort of idea with mapping reducibility in our last primer on Turing machines. Given a language $ B$ that we wanted to show as undecidable, we could show that if we had a Turing machine which decided $ B$, we could solve the halting problem. This is precisely the same idea: given a solution for $ B$ and an input for $ A$, we can construct in polynomial time an input for $ B$, use a decider for $ B$ to solve it, and then output accordingly. The only new thing is that the conversion of the input must happen in polynomial time.
Of course, this discussion was the proof of a clarifying lemma:
Lemma: If $ B \in \textup{P}$ and $ A \leq_p B$, then $ A \in \textup{P}$.
The proof is immediate, as $ B$ can be solved in polynomial time, and the conversion function runs in polynomial time. We leave the construction of an explicit Turing machine to decide $ A$ as an exercise to the reader.
To phrase things more colloquially, $ A \leq_p B$ is true if $ A$ is an *“*easier” problem than $ B$, hence justifying the less-than notation.
And now for the amazing part: there are problems in NP which are harder than all other problems in NP.
Definition: A language $ A \in \textup{NP}$ is called NP-complete if for all problems $ B \in \textup{NP}$, $ B \leq_p A$.
In other words, all problems in NP reduce to an NP-complete problem in polynomial time. In fact, we get another nice fact about NP-completeness that mirrors our observation about P above:
Lemma: If $ A$ is NP-complete and $ B \in \textup{NP}$ with $ A \leq_p B$, then $ B$ is NP-complete.
Obviously the composition of two polynomial-time reductions is a polynomial-time reduction, so we can conclude that all problems in NP which reduce to $ A$ also reduce to $ B$.
The cautious reader should be rather hesitant to believe that NP-complete problems should even exist. There is no reason we can’t come up with harder and harder problems, so why should there be a point after which we can’t quickly verify a solution?
Well, Stephen Cook proved in 1971 that there is an NP-complete problem, and shortly thereafter many more were found. Today, there are thousands of known NP-complete problems.
Perhaps unsurprisingly, Cook’s original NP-complete problem was N-Satisfiability (i.e., 3-Satisfiability without a constraint on the number of clauses or the form). Unfortunately the proof is quite difficult. We point the reader to the relevant Wikipedia page, and briefly mention the outline of a proof.
Given a nondeterministic polynomial-time Turing machine, we can bound the number of parallel computations and the length of each computation by $ n^k$ for some fixed $ k$. Then we create a $ n^k$ by $ n^k$ table of the configurations of the Turing machine (the i,j cell for the i-th branch of computation and the j-th step). From this, we can construct a monstrously enormous (yet polynomial in size) formula which has a satisfying assignment if and only if the Turing machine halts on some branch of computation in an accept state. Here is a table of the formulas needed to do this. In short, the formula traces the computation of the machine at each step, and ensures the transition function is honestly followed, the tape is reliably updated, and the head of each tape moves in the correct direction.
The reason we say it’s unsurprising that Satisfiability is NP-complete is because it’s commonly believed that every aspect of mathematics boils down to pure logic, although the process of doing so is entrenched in gory detail every step of the way. So it’s understandable that all problems in NP reduce to a problem about logic which is also in NP. We stipulate that other complexity classes likely have “complete” problems that are essentially questions about logical formulas.
A New Way to Find NP-Complete Problems
Now that we have established the NP-completeness of Satisfiability, we can do the same for other problems by reduction from a known NP-complete problem. First, we claim that 3-Satisfiability is NP-complete, and we leave the proof as an exercise to the reader (hint: reduce from regular Satisfiability by putting the formula into the right form).
Now given that 3-Sat is NP-complete, we will prove that k-Clique is NP-complete, by reduction from 3-Sat (in fact our conversion function will work for any formulas in conjunctive normal form, but 3 is enough).
Theorem: k-Clique is NP-complete.
Proof. Given a formula $ \varphi$ in conjunctive normal form, we construct an instance of k-Clique as follows. First, let $ k$ be the number of clauses in $ \varphi$. Construct a graph $ G_{\varphi}$ by creating a vertex for each literal term in $ \varphi$, and (to help visualization) organize them into columns by their originating clause, and label the vertex with its corresponding literal. Introduce an edge connecting two terms $ a, b$ in different columns when the formula $ a \wedge b$ is not a contradiction. In other words, it cannot be of the form $ x \wedge \overline{x}$ for some variable $ x$.
As a concrete example, the formula
$$\displaystyle (x \vee \overline{y} \vee z) \wedge (\overline{x} \vee \overline{z} \vee w)$$converts to the graph
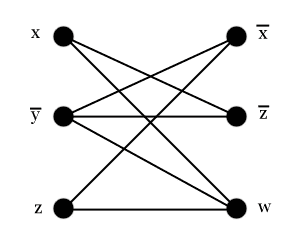
We claim that $ \varphi$ has a satisfying assignment of variables if and only if $ G_{\varphi}$ has a k-clique. Supposing there is a valid assignment of variables in $ \varphi$, then there must be one variable in each clause which is true (and hence $ k$ variables). This translates to $ k$ vertices in $ G_{\varphi}$, one vertex in each column which is true, and none of these vertices conflict with each other, so $ G_{\varphi}$ has an edge connecting each pair of the $ k$ vertices. Conversely, suppose $ G_{\varphi}$ has a k-clique. By our construction, two edges in the same column cannot be connected by and edge, and hence this k-clique must have one vertex in every column. If the vertex is labeled with a negation, assign it to the value $ F$ (so that the literal evaluates to true), and otherwise assign it the value $ T$. This gives a satisfying assignment of the variables of $ \varphi$, since each clause will evaluate to true under this assignment.
The final part of the proof is that the conversion function runs in polynomial time, and we claim this is obvious from the construction: if $ \varphi$ has $ n$ literals, then we create $ O(n)$ vertices and $ O(n^2)$ edges. The creation of each vertex and edge can be done in constant time, as can the verification that two literals do not conflict. $ \square$
Of course, this is a question about the possibilities of computers. Instead of giving a theoretical proof, why not just write a program to compute the conversion? Well we did just that, and the main body of the code turned out to be quite tidy:
;; n-sat-to-clique: formula -> (listof edge)
;; transform an input to n-sat to an input for clique
;; assume the input expression is in CNF, and that
(define (n-sat-to-clique expr)
(let* ([conjuncts (∧-conjuncts expr)]
[columns (map (λ (x) (∨-disjuncts x)) conjuncts)]
[labeled-columns (label-graph columns 1)]
[possible-edges (all-pairs-in-distinct-lists labeled-columns)])
(list->set (filter no-conflict? possible-edges))))
We have a data structure for a general formula (and provide a function to compute the conjunctive normal form of any expression), and a data structure for a graph (essentially, a list of pairs of labelled vertices), and so the process of checking all possible edges, and filtering out those which have no conflict, clearly takes $ O(n^2)$ time.
The rest of the code required to run the function above is available on this blog’s Github page.
Other NP-complete Problems, and P =? NP
In the real world NP-complete problems show up everywhere. Application domains include cryptography, financial portfolio and investment management, scheduling and operation dynamics, packing problems, chem- and bioinformatics, guarding art galleries, circuit design, compiler design, and even modelling social networks.
There are even many questions one can ask about games that turn out to be NP-complete in complexity. For instance, many questions about the classic game of Tetris are NP-complete, along with Minesweeper, FreeCell, Lemmings, Battleship, and Mastermind.
Now the big unsolved question is does P = NP? In other words, can any of these seemingly hard problems be solved quickly? The simple fact is, if the answer is yes to one such problem, then the answer is yes not only to all NP-complete problems, but to all problems in NP (as we saw in our lemma earlier). This is the heart of the million-dollar question that has been crowned the most difficult open problem in computer science to date. Almost everyone agrees that P and NP should not be equal, but nobody can prove it.
Of course, common people love to talk about P and NP because of all of the wild things that would happen if we suddenly discovered that P = NP. All widely used security systems would fail, internet transactions would no longer be safe, efficiency in industry would increase by orders of magnitude, we’d unlock the secrets of the human genome, we’d quickly solve open mathematical problems and find staggeringly ginormicon primes (ginormicon = gigantic + enormous + decepticon), governments will topple, rioting in the streets, the artificial intelligence singularity will occur, etc., etc.
But all of this is just media hype. The likely reality is that some problems are simply too hard to be solved in polynomial time in general, just as there are probably problems which have no polynomial-time verifiers (i.e., problems outside of NP), excluding the trivial problems which are undecidable. In the end, it’s just a matter of time until mathematics sorts everything out, or proves that it’s impossible to do so. Indeed, just two years ago this author remembers waking up to the news that there was a 100 page proof that P is not equal to NP, and moreover that Stephen Cook himself considered it a serious attempt. Unfortunately it turned out to have irreparable flaws, but failure made it no less exciting: this is how great mathematics is made.
On the other hand, there are cranks out there who have, for the last few years, been convinced that they have proved P = NP, but are ignorant of their own flaws and the rest of the world’s criticism. May Gauss have mercy on their mathematical souls.
Until next time!
Want to respond? Send me an email, post a webmention, or find me elsewhere on the internet.