During the 1950’s the famous mathematician Paul Erdős and Alfred Rényi put forth the concept of a random graph and in the subsequent years of study transformed the world of combinatorics. The random graph is the perfect example of a good mathematical definition: it’s simple, has surprisingly intricate structure, and yields many applications.
In this post we’ll explore basic facts about random graphs, slowly detail a proof on their applications to graph theory, and explore their more interesting properties computationally (a prelude to proofs about their structure). We assume the reader is familiar with the definition of a graph, which we’ve written about at length for non-mathematical audiences, and has some familiarity with undergraduate-level probability and combinatorics for the more mathematical sections of the post. We’ll do our best to remind the reader of these prerequisites as we go, and we welcome any clarification questions in the comment section.
The Erdős-Rényi Model
The definition of a random graph is simple enough that we need not defer it to the technical section of the article.
Definition: Given a positive integer $ n$ and a probability value $ 0 \leq p \leq 1$, define the graph $ G(n,p)$ to be the undirected graph on $ n$ vertices whose edges are chosen as follows. For all pairs of vertices $ v,w$ there is an edge $ (v,w)$ with probability $ p$.
Of course, there is no single random graph. What we’ve described here is a process for constructing a graph. We create a set of $ n$ vertices, and for each possible pair of vertices we flip a coin (often a biased coin) to determine if we should add an edge connecting them. Indeed, every graph can be made by this process if one is sufficiently lucky (or unlucky), but it’s very unlikely that we will have no edges at all if $ p$ is large enough. So $ G(n,p)$ is really a probability distribution over the set of all possible graphs on $ n$ vertices. We commit a horrendous abuse of notation by saying $ G$ or $ G(n,p)$ is a random graph instead of saying that $ G$ is sampled from the distribution. The reader will get used to it in time.
Why Do We Care?
Random graphs of all sorts (not just Erdős’s model) find applications in two very different worlds. The first is pure combinatorics, and the second is in the analysis of networks of all kinds.
In combinatorics we often wonder if graphs exist with certain properties. For instance, in graph theory we have the notion of graph colorability: can we color the vertices of a graph with $ k$ colors so that none of its edges are monochromatic? (See this blog’s primer on graph coloring for more) Indeed, coloring is known to be a very difficult problem on general graphs. The problem of determining whether a graph can be colored with a fixed number of colors has no known efficient algorithm; it is NP-complete. Even worse, much of our intuition about graphs fails for graph coloring. We would expect that sparse-looking graphs can be colored with fewer colors than dense graphs. One naive way to measure sparsity of a graph is to measure the length of its shortest cycle (recall that a cycle is a path which starts and ends at the same vertex). This measurement is called the girth of a graph. But Paul Erdős proved using random graphs, as we will momentarily, that for any choice of integers $ g,k$ there are graphs of girth $ \geq g$ which cannot be colored with fewer than $ k$ colors. Preventing short cycles in graphs doesn’t make coloring easier.
The role that random graphs play in this picture is to give us ways to ensure the existence of graphs with certain properties, even if we don’t know how to construct an example of such a graph. Indeed, for every theorem proved using random graphs, there is a theorem (or open problem) concerning how to algorithmically construct those graphs which are known to exist.
Pure combinatorics may not seem very useful to the real world, but models of random graphs (even those beyond the Erdős-Rényi model) are quite relevant. Here is a simple example. One can take a Facebook user $ u$ and form a graph of that users network of immediate friends $ N(u)$ (excluding $ u$ itself), where vertices are people and two people are connected by an edge if they are mutual friends; call this the user’s friendship neighborhood. It turns out that the characteristics of the average Facebook user’s friendship neighborhood resembles a random graph. So understanding random graphs helps us understand the structure of small networks of friends. If we’re particularly insightful, we can do quite useful things like identify anomalies, such as duplicitous accounts, which deviate quite far from the expected model. They can also help discover trends or identify characteristics that can allow for more accurate ad targeting. For more details on how such an idea is translated into mathematics and code, see Modularity (we plan to talk about modularity on this blog in the near future; lots of great linear algebra there!).
Random graphs, when they exhibit observed phenomena, have important philosophical consequences. From a bird’s-eye view, there are two camps of scientists. The first are those who care about leveraging empirically observed phenomena to solve problems. Many statisticians fit into this realm: they do wonderful magic with data fit to certain distributions, but they often don’t know and don’t care whether the data they use truly has their assumed properties. The other camp is those who want to discover generative models for the data with theoretical principles. This is more like theoretical physics, where we invent an arguably computational notion of gravity whose consequences explain our observations.
For applied purposes, the Erdős-Rényi random graph model is in the second camp. In particular, if something fits in the Erdős-Rényi model, then it’s both highly structured (as we will make clear in the sequel) and “essentially random.” Bringing back the example of Facebook, this says that most people in the average user’s immediate friendship neighborhood are essentially the same and essentially random in their friendships among the friends of $ u$. This is not quite correct, but it’s close enough to motivate our investigation of random graph models. Indeed, even Paul Erdős in his landmark paper mentioned that equiprobability among all vertices in a graph is unrealistic. See this survey for a more thorough (and advanced!) overview, and we promise to cover models which better represent social phenomena in the future.
So lets go ahead and look at a technical proof using random graphs from combinatorics, and then write some programs to generate random graphs.
Girth and Chromatic Number, and Counting Triangles
As a fair warning, this proof has a lot of moving parts. Skip to the next section if you’re eager to see some programs.
Say we have a $ k$ and a $ g$, and we wonder whether a graph can exist which simultaneously has no cycles of length less than $ g$ (the girth) and needs at least $ k$ colors to color. The following theorem settles this question affirmatively. A bit of terminology: the *chromatic number of a graph $ G$, denoted $ \chi(G)$, is the smallest number of colors needed to properly color $ G$.
Theorem: For any natural numbers $ k,g$, there exist graphs of chromatic number at least $ k$ and girth at least $ g$.
Proof. Taking our cue from random graphs, let’s see what the probability is that a random graph $ G(n,p)$ on $ n$ vertices will have our desired properties. Or easier, what’s the chance that it will not have the right properties? This is essentially a fancy counting argument, but it’s nicer if we phrase it in the language of probability theory.
The proof has a few twists and turns for those uninitiated to the probabilistic method of proof. First, we will look at an arbitrary $ G(n,p)$ (where $ n,p$ are variable) and ask two questions about it: what is the expected number of short cycles, and what is the expected “independence number” (which we will see is related to coloring). We’ll then pick a value of $ p$, depending crucially on $ n$, which makes both of these expectations small. Next, we’ll use the fact that if the probability that $ G(n,p)$ doesn’t have our properties is strictly less than 1, then there has to be some instance in our probability space which has those properties (if no instance had the property, then the probability would be one!). Though we will not know what the graphs look like, their existence is enough to prove the theorem.
So let’s start with cycles. If we’re given a desired girth of $ g$, the expected number of cycles of length $ \leq g$ in $ G(n,p)$ can be bounded by $ (np)^{g+1}/(np-1)$. To see this, the two main points are how to count the number of ways to pick $ k$ vertices in order to form a cycle, and a typical fact about sums of powers. Indeed, we can think of a cycle of length $ k$ as a way to seat a choice of $ k$ people around a circular table. There are $ \binom{n}{k}$ possible groups of people, and $ (k-1)!$ ways to seat one group. If we fix $ k$ and let $ n$ grow, then the product $ \binom{n}{k}(k-1)!$ will eventually be smaller than $ n^k$ (actually, this happens almost immediately in almost all cases). For each such choice of an ordering, the probability of the needed edges occurring to form a cycle is $ p^j$, since all edges must occur independently of each other with probability $ p$.
So the probability that we get a cycle of $ j$ vertices is
$$\displaystyle \binom{n}{j}(j-1)!p^j$$And by the reasoning above we can bound this by $ n^jp^j$. Summing over all numbers $ j = 3, \dots, g$ (we are secretly using the union bound), we bound the expected number of cycles of length $ \leq g$ from above:
$$\displaystyle \sum_{j=3}^g n^j p^j < \sum_{j=0}^g n^j p^j = \frac{(np)^{g+1}}{np – 1}$$Since we want relatively few cycles to occur, we want it to be the case that the last quantity, $ (np)^{j+1}/(np-1)$, goes to zero as $ n$ goes to infinity. One trick is to pick $ p$ depending on $ n$. If $ p = n^l$, our upper bound becomes $ n^{(l+1)(g+1)} / (n^{1+l} – 1)$, and if we want the quantity to tend to zero it must be that $ (l+1)(g+1) < 1$. Solving this we get that $ -1 < l < \frac{1}{g+1} – 1 < 0$. Pick such an $ l$ (it doesn’t matter which), and keep this in mind: for our choice of $ p$, the expected number of cycles goes to zero as $ n$ tends to infinity.
On the other hand, we want to make sure that such a graph has high chromatic number. To do this we’ll look at a related property: the size of the largest independent set. An independent set of a graph $ G = (V,E)$ is a set of vertices $ S \subset V$ so that there are no edges in $ E$ between vertices of $ S$. We call $ \alpha(G)$ the size of the largest independent set. The values $ \alpha(G)$ and $ \chi(G)$ are related, because any time you have an independent set you can color all the vertices with a single color. In particular, this proves the inequality $ \chi(G) \alpha(G) \geq n$, the number of vertices of $ G$, or equivalently $ \chi(G) \geq n / \alpha(G)$. So if we want to ensure $ \chi(G)$ is large, it suffices to show $ \alpha(G)$ is small (rigorously, $ \alpha(G) \leq n / k$ implies $ \chi(G) \geq k$).
The expected number of independent sets (again using the union bound) is at most the product of the number of possible independent sets and the probability of one of these having no edges. We let $ r$ be arbitrary and look at independent sets of size $ r$ Since there are $ \binom{n}{r}$ sets and each has a probability $ (1-p)^{\binom{r}{2}}$ of being independent, we get the probability that there is an independent set of size $ r$ is bounded by
$$\displaystyle \textup{P}(\alpha(G) \geq r) \leq \binom{n}{r}(1-p)^{\binom{r}{2}}$$We use the fact that $ 1-x < e^{-x}$ for all $ x$ to translate the $ (1-p)$ part. Combining this with the usual $ \binom{n}{r} \leq n^r$ we get the probability of having an independent set of size $ r$ at most
$$\displaystyle \textup{P}(\alpha(G) \geq r) \leq \displaystyle n^re^{-pr(r-1)/2}$$Now again we want to pick $ r$ so that this quantity goes to zero asymptotically, and it’s not hard to see that $ r = \frac{3}{p}\log(n)$ is good enough. With a little arithmetic we get the probability is at most $ n^{(1-a)/2}$, where $ a > 1$.
So now we have two statements: the expected number of short cycles goes to zero, and the probability that there is an independent set of size at least $ r$ goes to zero. If we pick a large enough $ n$, then the expected number of short cycles is less than $ n/5$, and using Markov’s inequality we see that the probability that there are more than $ n/2$ cycles of length at most $ g$ is strictly less than 1/2. At the same time, if we pick a large enough $ n$ then $ \alpha(G) \geq r$ with probability strictly less than 1/2. Combining these two (once more with the union bound), we get
$$\textup{P}(\textup{at least } n/2 \textup{ cycles of length } \leq g \textup{ and } \alpha(G) \geq r) < 1$$Now we can conclude that for all sufficiently large $ n$ there has to be a graph on at least $ n$ vertices which has neither of these two properties! Pick one and call it $ G$. Now $ G$ still has cycles of length $ \leq g$, but we can fix that by removing a vertex from each short cycle (it doesn’t matter which). Call this new graph $ G’$. How does this operation affect independent sets, i.e. what is $ \alpha(G’)$? Well removing vertices can only decrease the size of the largest independent set. So by our earlier inequality, and calling $ n’$ the number of vertices of $ G’$, we can make a statement about the chromatic number:
$$\displaystyle \chi(G’) \geq \frac{n’}{\alpha(G’)} \geq \frac{n/2}{\log(n) 3/p} = \frac{n/2}{3n^l \log(n)} = \frac{n^{1-l}}{6 \log(n)}$$Since $ -1 < l < 0$ the numerator grows asymptotically faster than the denominator, and so for sufficiently large $ n$ the chromatic number will be larger than any $ k$ we wish. Hence we have found a graph with girth at least $ g$ and chromatic number at least $ k$.
$$\square$$Connected Components
The statistical properties of a random graph are often quite easy to reason about. For instance, the degree of each vertex in $ G(n,p)$ is $ np$ in expectation. Local properties like this are easy, but global properties are a priori very mysterious. One natural question we can ask in this vein is: when is $ G(n,p)$ connected? We would very much expect the answer to depend on how $ p$ changes in relation to $ n$. For instance, $ p$ might look like $ p(n) = 1/n^2$ or $ \log(n) / n$ or something similar. We could ask the following question:
As $ n$ tends to infinity, what limiting proportion of random graphs $ G(n,p)$ are connected?
Certainly for some $ p(n)$ which are egregiously small (for example, $ p(n) = 0$), the answer will be that no graphs are connected. On the other extreme, if $ p(n) = 1$ then all graphs will be connected (and complete graphs, at that!). So our goal is to study the transition phase between when the graphs are disconnected and when they are connected. A priori this boundary could be a gradual slope, where the proportion grows from zero to one, or it could be a sharp jump. Next time, we’ll formally state and prove the truth, but for now let’s see if we can figure out which answer to expect by writing an exploratory program.
We wrote the code for this post in Python, and as usual it is all available for download on this blog’s Github page.
We start with a very basic Node class to represent each vertex in a graph, and a function to generate random graphs
import random
class Node:
def __init__(self, index):
self.index = index
self.neighbors = []
def __repr__(self):
return repr(self.index)
def randomGraph(n,p):
vertices = [Node(i) for i in range(n)]
edges = [(i,j) for i in xrange(n) for j in xrange(i) if random.random() < p]
for (i,j) in edges:
vertices[i].neighbors.append(vertices[j])
vertices[j].neighbors.append(vertices[i])
return vertices
The randomGraph function simply creates a list of edges chosen uniformly at random from all possible edges, and then constructs the corresponding graph. Next we have a familiar sight: the depth-first search. We use it to compute the graph components one by one (until all vertices have been found in some run of a DFS).
def dfsComponent(node, visited):
for v in node.neighbors:
if v not in visited:
visited.add(v)
dfsComponent(v, visited)
def connectedComponents(vertices):
components = []
cumulativeVisited = set()
for v in vertices:
if v not in cumulativeVisited:
componentVisited = set([v])
dfsComponent(v, componentVisited)
components.append(componentVisited)
cumulativeVisited |= componentVisited
return components
The dfsComponent function simply searches in breadth-first fashion, adding every vertex it finds to the “visited” set. The connectedComponents function keeps track of the list of components found so far, as well as the cumulative set of all vertices found in any run of bfsComponent. Hence, as we iterate through the vertices we can ignore vertices we’ve found in previous runs of bfsComponent. The “x |= y” notation is python shorthand for updating x via a union with y.
Finally, we can make a graph of the largest component of (independently generated) random graphs as the probability of an edge varies.
def sizeOfLargestComponent(vertices):
return max(len(c) for c in connectedComponents(vertices))
def graphLargestComponentSize(n, theRange):
return [(p, sizeOfLargestComponent(randomGraph(n, p))) for p in theRange]
Running this code and plotting it for $ p$ varying from zero to 0.5 gives the following graph.
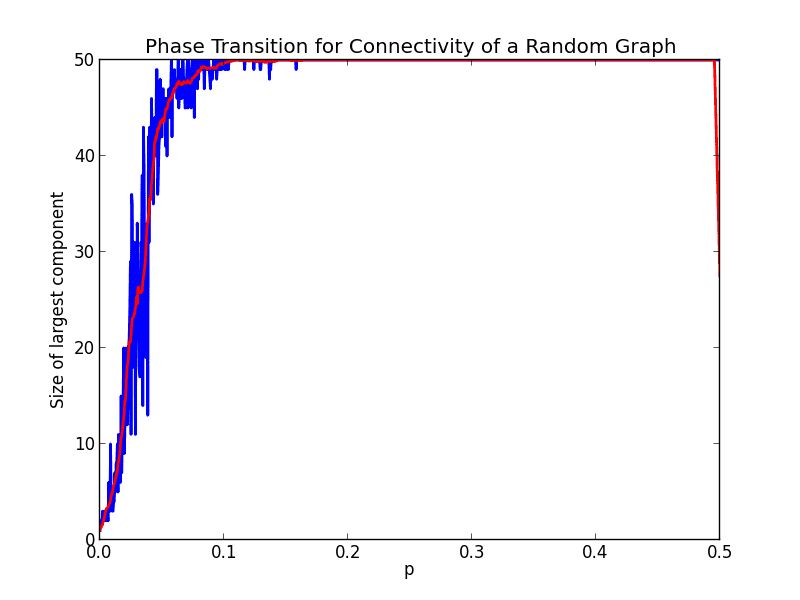
zoomedout-50-1000
The blue line is the size of the largest component, and the red line gives a moving average estimate of the data. As we can see, there is a very sharp jump peaking at $ p=0.1$ at which point the whole graph is connected. It would appear there is a relatively quick “phase transition” happening here. Let’s zoom in closer on the interesting part.
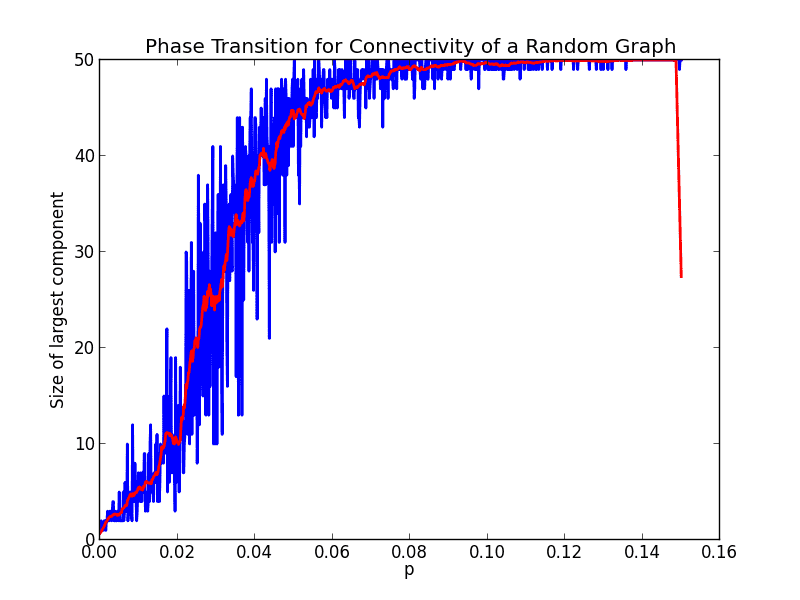
zoomedin-50-1000
It looks like the transition begins around 0.02, and finishes at around 0.1. Interesting… Let’s change the parameters a bit, and increase the size of the graph. Here’s the same chart (in the same range of $ p$ values) for a graph with a hundred vertices.
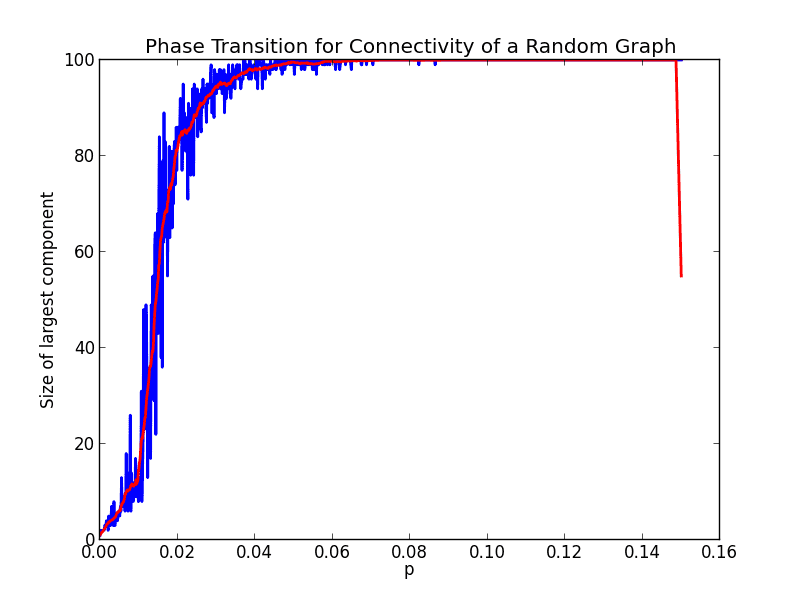
zoomedin-100-1000
Now the phase transition appears to have shifted to about $ (0.01, 0.05)$, which is about multiplying the endpoints of the phase transition interval above by 1/2. The plot thickens… Once more, let’s move up to a graph on 500 vertices.
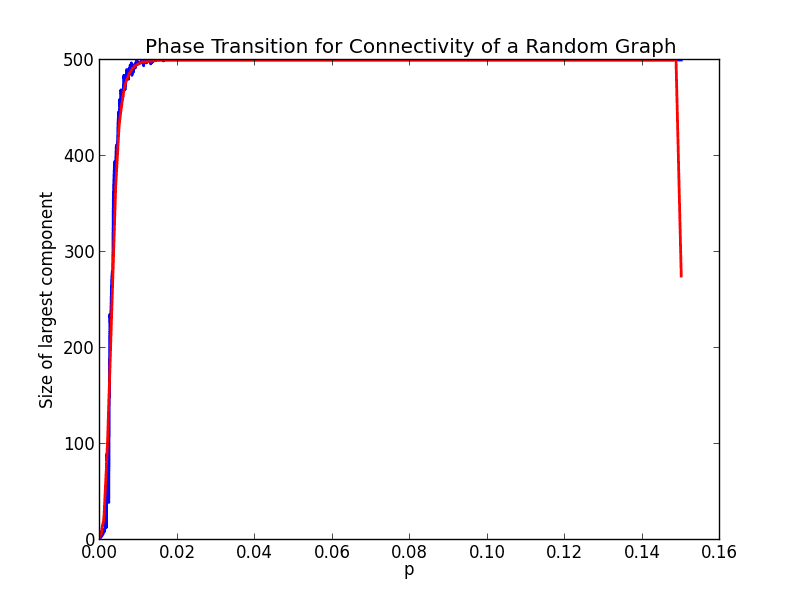
zoomedin-5000-1000
Again it’s too hard to see, so let’s zoom in.
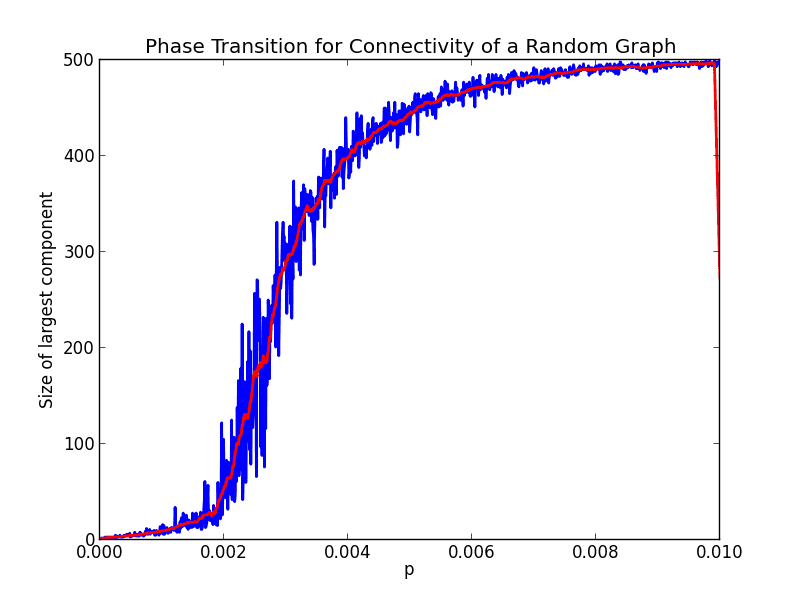
zoomedin-500-1000
This one looks like the transition starts at 0.002 and ends at 0.01. This is a 5-fold decrease from the previous one, and we increased the number of vertices by 5. Could this be a pattern? Here’s a conjecture to formalize it:
Conjecture: The random graph $ G(n,p)$ enters a phase transition at $ p=1/n$ and becomes connected almost surely at $ p=5/n$.
This is not quite rigorous enough to be a true conjecture, but it sums up our intuition that we’ve learned so far. Just to back this up even further, here’s an animation showing the progression of the phase transition as $ n = 20 \dots 500$ in steps of twenty. Note that the $ p$ range is changing to maintain our conjectured window.
phase-transition-n-grows
Looks pretty good. Next time we’ll see some formal mathematics validating our intuition (albeit reformulated in a nicer way), and we’ll continue to investigate other random graph models.
Until then!
Want to respond? Send me an email, post a webmention, or find me elsewhere on the internet.