For a while I’ve been meaning to do some more advanced posts on optimization problems of all flavors. One technique that comes up over and over again is Lagrange multipliers, so this post is going to be a leisurely reminder of that technique. I often forget how to do these basic calculus-type things, so it’s good practice.
We will assume something about the reader’s knowledge, but it’s a short list: know how to operate with vectors and the dot product, know how to take a partial derivative, and know that in single-variable calculus the local maxima and minima of a differentiable function $ f(x)$ occur when the derivative $ f'(x)$ vanishes. All of the functions we’ll work with in this post will have infinitely many derivatives (i.e. smooth). So things will be nice.
The Gradient
The gradient of a multivariable function is the natural extension of the derivative of a single-variable function. If $ f(x_1, \dots, x_n)$ is a differentiable function, the data of the gradient of $ f$ consists of all of the partial derivatives $ \partial f / \partial x_i$. It’s usually written as a vector
$$\displaystyle \nabla f = \left ( \frac{\partial f}{\partial x_1}, \dots, \frac{\partial f}{\partial x_n} \right )$$To make things easier for ourselves, we’ll just call $ f$ a function $ f(x)$ and understand $ x$ to be a vector in $ \mathbb{R}^n$.
We can also think of $ \nabla f$ as a function which takes in vectors and spits out vectors, by plugging in the input vector into each $ \partial f / \partial x_i$. And the reason we do this is because it lets us describe the derivative of $ f$ at a point as a linear map based on the gradient. That is, if we want to know how fast $ f$ is growing along a particular vector $ v$ and at a particular point $ (x, f(x))$, we can just take a dot product of $ v$ with $ \nabla f(x)$. I like to call dot products inner products, and use the notation $ \left \langle \nabla f(x), v \right \rangle$. Here $ v$ is a vector in $ \mathbb{R}^n$ which we think of as “tangent vectors” to the surface defined by $ f$. And if we scale $ v$ bigger or smaller, the value of the derivative scales with it (of course, because the derivative is a linear map!). Usually we use unit vectors to represent directions, but there’s no reason we have to. Calculus textbooks often require this to define a “directional derivative,” but perhaps it is better to understand the linear algebra over memorizing these arbitrary choices.
For example, let $ f(x,y,z) = xyz$. Then $ \nabla f = (yz, xz, xy)$, and $ \nabla f(1,2,1) = (2, 1, 2)$. Now if we pick a vector to go along, say, $ v = (0,-1,1)$, we get the derivative of $ f$ along $ v$ is $ \left \langle (2,1,2), (0,-1,1) \right \rangle = 1$.
As importantly as computing derivatives is finding where the derivative is zero, and the geometry of the gradient can help us here. Specifically, if we think of our function $ f$ as a surface sitting in $ \mathbb{R}^{n+1}$ (as in the picture below), it’s not hard to see that the gradient vector points in the direction of steepest ascent of $ f$. How do we know this? Well if you fix a point $ (x_1, \dots, x_n)$ and you’re forced to use a vector $ v$ of the same magnitude as $ \nabla f(x)$, how can you maximize the inner product $ \left \langle \nabla f(x), v \right \rangle$? Well, you just pick $ v$ to be equal to $ \nabla f(x)$, of course! This will turn the dot product into the square norm of $ \nabla f(x)$.
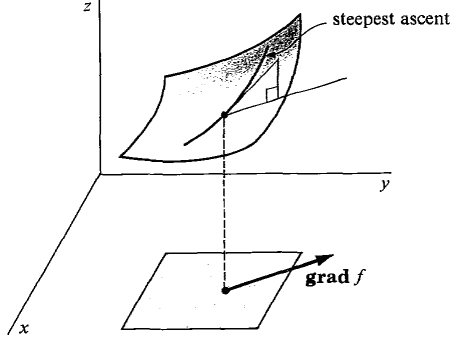
The gradient points in the direction of steepest ascent
More generally, the operation of an inner product $ \left \langle -, v \right \rangle$ is geometrically the size of the projection of the argument onto $ v$ (scaled by the size of $ v$), and projections of a vector $ w$ onto different directions than $ w$ can only be smaller in magnitude than $ w$. Another way to see this is to know the “alternative” formula for the dot product
$$\displaystyle \left \langle v,w \right \rangle = \left \| v \right \| \left \| w \right \| \cos(\theta)$$where $ \theta$ is the angle between the vectors (in $ \mathbb{R}^n$). We might not know how to get that angle, and in this post we don’t care, but we do know that $ \cos(\theta)$ is between -1 and 1. And so if $ v$ is fixed and we can’t change the norm of $ w$ but only its direction, we will maximize the dot product when the two vectors point in the same direction, when $ \theta$ is zero.
All of this is just to say that the gradient at a point can be interpreted as having a specific direction. It’s the direction of steepest ascent of the surface $ f$, and it’s size tells you how steep $ f$ is at that point. The opposite direction is the direction of steepest descent, and the orthogonal directions (when $ \theta = \pi /2$) have derivative zero.
Now what happens if we’re at a local minimum or maximum? Well it’s necessary that $ f$ is flat, and so by our discussion above the derivatives in all directions must be zero. It’s a basic linear algebra proof to show that this means the gradient is the zero vector. You can prove this by asking what sorts of vectors $ w$ have a dot product of zero with all other vectors $ v$?
Now once we have a local max or a local min, how do we tell which? The answer is actually a bit complicated, and it requires you to inspect the eigenvalues of the Hessian of $ f$. We won’t dally on eigenvalues except to explain the idea in brief: for an $ n$ variable function $ f$ the Hessian of $ f$ at $ x$ is an $ n$-by-$ n$ matrix where the $ i,j$ entry is the value of $ (\partial f / \partial x_i \partial x_j )(x)$. It just so turns out that if this matrix has only positive eigenvalues, then $ x$ is a local minimum. If the eigenvalues are all negative, it’s a local max. If some are negative and some are positive, then it’s a saddle point. And if zero is an eigenvalue then we’re screwed and can’t conclude anything without more work.
But all of this Hessian business isn’t particularly important for us, because most of our applications of the Lagrangian will work with functions where we already know that there is a unique global maximum or minimum. Finding where the gradient is zero is enough. As much as this author stresses the importance of linear algebra, we simply won’t need to compute any eigenvalues for this one.
What we will need to do is look at optimizing functions which are constrained by some equality conditions. This is where Lagrangians come into play.
Constrained by Equality
Often times we will want to find a minimum or maximum of a function $ f(x)$, but we will have additional constraints. The simplest kind is an equality constraint.
For example, we might want to find the maximum of the function $ f(x, y, z) = xyz$ requiring that the point $ (x,y,z)$ lies on the unit circle. One could write this in a “canonical form”
maximize $ xyz$ subject to $ x^2 + y^2 + z^2 = 1$
Way back in the scientific revolution, Fermat discovered a technique to solve such problems that was later generalized by Lagrange. The idea is to combine these constraints into one function whose gradient provides enough information to find a maximum. Clearly such information needs to include two things: that the gradient of $ xyz$ is zero, and that the constraint is satisfied.
First we rewrite the constraints as $ g(x,y,z) = x^2 + y^2 + x^2 – 1 = 0$, because when we’re dealing with gradients we want things to be zero. Then we form the Lagrangian of the problem. We’ll give a precise definition in a minute, but it looks like this:
$$L(x,y,z,\lambda) = xyz + \lambda(x^2 + y^2 + z^2 – 1)$$That is, we’ve added a new variable $ \lambda$ and added the two functions together. Let’s see what happens when we take a gradient:
$$\displaystyle \frac{\partial L}{\partial x} = yz + \lambda 2x$$ $$\displaystyle \frac{\partial L}{\partial y} = xz + \lambda 2y$$ $$\displaystyle \frac{\partial L}{\partial z} = xy + \lambda 2z$$ $$\displaystyle \frac{\partial L}{\partial \lambda} = x^2 + y^2 + z^2 – 1$$Now if we require the gradient to be zero, the last equation is simply the original constraint, and the first three equations say that $ \nabla f (x,y,z) = \lambda \nabla g (x,y,z)$. In other words, we’re saying that the two gradients must point in the same direction for the function to provide a maximum. Solving for where these equations vanish gives some trivial solutions (one variable is $ \pm 1$ and the rest zero, and $ \lambda = 0$), and a solution defined by $ x^2 = y^2 = z^2 = 1/3$ which is clearly the maximal of the choices.
Indeed, this will work in general, and you can see a geometric and analytic proof in these notes.
Specifically, if we have an optimization problem defined by an objective function $ f(x)$ to optimize, and a set of $ k$ equality constraints $ g_i(x) = 0$, then we can form the Lagrangian
$$\displaystyle L(x, \lambda_1, \dots, \lambda_k) = f(x) + \sum_{i=1}^k \lambda_i g_i(x)$$And then a theorem of Lagrange is that all optimal solutions $ x^*$ to the problem satisfy $ \nabla L(x^*, \lambda_1, \dots, \lambda_k) = 0$ for some choice of $ \lambda _i$. But then you have to go solve the system and figure out which of the solutions gives you your optimum.
Convexity
As it turns out, there are some additional constraints you can add to your problem to guarantee your system has a solution. One nice condition is that $ f(x)$ is convex. A function is convex if any point on a line segment between two points $ (x,f(x))$ and $ (y,f(y))$ has a value greater than $ f$. In other words, for all $ 0 \leq t \leq 1$:
$$\displaystyle f(tx + (1-t)y) \leq tf(x) + (1-t)f(y)$$Some important examples of convex functions: exponentials, quadratics whose leading coefficient is positive, square norms of a vector variable, and linear functions.
Convex functions have this nice property that they have a unique local minimum value, and hence it must also be the global minimum. Why is this? Well if you have a local minimum $ x$, and any other point $ y$, then by virtue of being a local minimum there is some $ t$ sufficiently close to 1 so that:
$$\displaystyle f(x) \leq f(tx + (1-t)y) \leq tf(x) + (1-t)f(y)$$And rearranging we get
$$\displaystyle (1-t)f(x) \leq (1-t)f(y)$$So $ f(x) \leq f(y)$, and since $ y$ was arbitrary then $ x$ is the global minimum.
This alleviates our problem of having to sort through multiple solutions, and in particular it helps us to write programs to solve optimization problems: we know that techniques like gradient descent will never converge to a false local minimum.
That’s all for now! The next question we might shadowily ask: what happens if we add inequality constraints?
Want to respond? Send me an email, post a webmention, or find me elsewhere on the internet.