
satellite
One of the most interesting questions posed in the last thirty years of computer science is to ask how much “information” must be communicated between two parties in order for them to jointly compute something. One can imagine these two parties living on distant planets, so that the cost of communicating any amount of information is very expensive, but each person has an integral component of the answer that the other does not.
Since this question was originally posed by Andrew Yao in 1979, it has led to a flurry of applications in many areas of mathematics and computer science. In particular it has become a standard tool for proving lower bounds in many settings such as circuit design and streaming algorithms. And if there’s anything theory folks love more than a problem that can be solved by an efficient algorithm, it’s a proof that a problem cannot be solved by any efficient algorithm (that’s what I mean by “lower bound”).
Despite its huge applicability, the basic results in this area are elementary. In this post we’ll cover those basics, but once you get past these basic ideas and their natural extensions you quickly approach the state of the art and open research problems. Attempts to tackle these problems in recent years have used sophisticated techniques in Fourier analysis, Ramsey theory, and geometry. This makes it a very fun and exciting field.
As a quick side note before we start, the question we’re asking is different from the one of determining the information content of a specific message. That is the domain of information theory, which was posed (and answered) decades earlier. Here we’re trying to determine the complexity of a problem, where more complex messages require more information about their inputs.
The Basic Two-Player Model
The most basic protocol is simple enough to describe over a dinner table. Alice and Bob each have one piece of information $ x,y$, respectively, say they each have a number. And together they want to compute some operation that depends on both their inputs, for example whether $ x > y$. But in the beginning Alice has access only to her number $ x$, and knows nothing about $ y$. So Alice sends Bob a few bits. Depending on the message Bob computes something and replies, and this repeats until they have computed an answer. The question is: what is the minimum number of bits they need to exchange in order for both of them to be able to compute the right answer?
There are a few things to clarify here: we’re assuming that Alice and Bob have agreed on a protocol for sending information before they ever saw their individual numbers. So imagine ten years earlier Alice and Bob were on the same planet, and they agreed on the rules they’d follow for sending/replying information once they got their numbers. In other words, we’re making a worst-case assumption on Alice and Bob’s inputs, and as usual it will be measured as a function of $ n$, the lengths of their inputs. Then we take a minimum (asymptotically) over all possible protocols they could follow, and this value is the “communication complexity” of the problem. Computing the exact communication complexity of a given problem is no simple task, since there’s always the nagging question of whether there’s some cleverer protocol than the one you came up with. So most of the results are bounds on the communication complexity of a problem.
Indeed, we can give our first simple bound for the “$ x$ greater than $ y$” problem we posed above. Say the strings $ x,y$ both have $ n$ bits. What Alice does is send her entire string $ x$ to Bob, and Bob then computes the answer and sends the answer bit back to Alice. This requires $ n + 1$ bits of communication. This proves that the communication complexity of “$ x > y$” is bounded from above by $ n+1$. A much harder question is, can we do any better?
To make any progress on upper or lower bounds we need to be a bit more formal about the communication model. Basically, the useful analysis happens when the players alternate sending single bits, and this is only off by small constant factors from a more general model. This is the asymptotic analysis, that we only distinguish between things like linear complexity $ O(n)$ versus sublinear options like $ \log(n)$ or $ \sqrt{n}$ or even constant complexity $ O(1)$. Indeed, the protocol we described for $ x > y$ is the stupidest possible protocol for the problem, and it’s actually valid for any problem. For this problem it happens to be optimal, but we’re just trying to emphasize that nontrivial bounds are all sub-linear in the size of the inputs.
On to the formal model.
Definition: A player is a computationally unbounded Turing machine.
And we really mean unbounded. Our players have no time or space constraints, and if they want they can solve undecidable problems like the halting problem or computing Kolmogorov complexity. This is to emphasize that the critical resource is the amount of communication between players. Moreover, it gives us a hint that lower bounds in this model won’t come form computational intractability, but instead will be “information-theoretic.”
Definition: Let $ \Sigma^*$ be the set of all binary strings. A communication protocol is a pair of functions $ A,B: \Sigma^* \times \Sigma^* \to \{ 0,1 \}$.
The input to these functions $ A(x, h)$ should be thought of as follows: $ x$ is the player’s secret input and $ h$ is the communication history so far. The output is the single bit that they will send in that round (which can be determined by the length of $ h$ since only one bit is sent in each round). The protocol then runs by having Alice send $ b_1 = A(x, \{ \})$ to Bob, then Bob replies with $ b_2 = B(y, b_1)$, Alice continues with $ b_3 = A(x, b_1b_2)$, and so on. We implicitly understand that the content of a communication protocol includes a termination condition, but we’ll omit this from the notation. We call the length of the protocol the number of rounds.
Definition: A communication protocol $ A,B$ is said to be valid for a boolean function $ f(x,y)$ if for all strings $ x, y$, the protocol for $ A, B$ terminates on some round $ t$ with $ b_t = 1$ if and only if $ f(x,y) = 1$.
So to define the communication complexity, we let the function $ L_{A,B}(n)$ be the maximum length of the protocol $ A, B$ when run on strings of length $ n$ (the worst-case for a given input size). Then the communication complexity of a function $ f$ is the minimum of $ L_{A,B}$ over all valid protocols $ A, B$. In symbols,
$$\displaystyle CC_f(n) = \min_{A,B \textup{ is valid for } f} L_{A,B}(n)$$We will often abuse the notation by writing the communication complexity of a function as $ CC(f)$, understanding that it’s measured asymptotically as a function of $ n$.
Matrices and Lower Bounds
Let’s prove a lower bound, that to compute the equality function you need to send a linear number of bits in the worst case. In doing this we’ll develop a general algebraic tool.
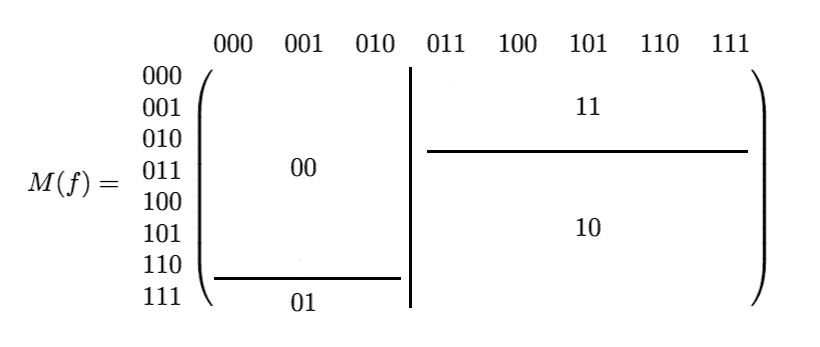
So let’s write out the function $ f$ as a binary matrix $ M(f)$ in the following way. Write all $ 2^n$ inputs of length $ n$ in some fixed order along the rows and columns of the matrix, and let entry $ i,j$ be the value of $ f(i,j)$. For example, the 6-bit function $ f$ which computes whether the majority of the two player’s bits are ones looks like this:

maj-matrix
The key insight to remember is that if the matrix of a function has a nice structure, then one needs very little communication to compute it. Let’s see why.
Say in the first round the row player sends a bit $ b$. This splits the matrix into two submatrices $ A_0, A_1$ by picking the rows of $ A_0$ to be those inputs for which the row player sends a $ b=0$, and likewise for $ A_1$ with $ b=1$. If you’re willing to rearrange the rows of the matrix so that $ A_0$ and $ A_1$ stack on top of each other, then this splits the matrix into two rectangles. Now we can switch to the column player and see which bit he sends in reply to each of the possible choices for $ b$ (say he sends back $ b’$). This separately splits each of $ A_0, A_1$ into two subrectangles corresponding to which inputs for the column player make him send the specific value of $ b’$. Continuing in this fashion we recurse until we find a submatrix consisting entirely of ones or entirely of zeros, and then we can say with certainty what the value of the function $ f$ is.
It’s difficult to visualize because every time we subdivide we move around the rows and columns within the submatrix corresponding to the inputs for each player. So the following would be a possible subdivision of an 8×8 matrix (with the values in the rectangles denoting which communicated bits got you there), but it’s sort of a strange one because we didn’t move the inputs around at all. It’s just a visual aid.
maj-matrix-subdivision
If we do this for $ t$ steps we get $ 2^t$ subrectangles. A crucial fact is that any valid communication protocol for a function has to give a subdivision of the matrix where all the rectangles are constant. or else there would be two pairs of inputs $ (x,y), (x’, y’)$, which are labeled identically by the communication protocol, but which have different values under $ f$.
So naturally one expects the communication complexity of $ f$ would require as many steps as there are steps in the best decomposition, that is, the decomposition with the fewest levels of subdivision. Indeed, we’ll prove this and introduce some notation to make the discourse less clumsy.
Definition: For an $ m \times n$ matrix $ M$, a rectangle is a submatrix $ A \times B$ where $ A \subset \{ 1, \dots m \}, B \subset \{ 1, \dots, n \}$. A rectangle is called monochromatic if all entires in the corresponding submatrix $ \left.M\right|_{A \times B}$ are the same. A monochromatic tiling of $ M$ is a partition of $ M$ into disjoint monochromatic rectangles. Define $ \chi(f)$ to be the minimum number of rectangles in any monochromatic tiling of $ M(f)$.
As we said, if there are $ t$ steps in a valid communication protocol for $ f$, then there are $ 2^t$ rectangles in the corresponding monochromatic tiling of $ M(f)$. Here is an easy consequence of this.
Proposition: If $ f$ has communication complexity $ CC(f)$, then there is a monochromatic tiling of $ M(f)$ with at most $ 2^{CC(f)}$ rectangles. In particular, $ \log(\chi(f)) \leq CC(f)$.
Proof. Pick any protocol that achieves the communication complexity of $ f$, and apply the process we described above to subdivide $ M(f)$. This will take exactly $ CC(f)$, and produce no more than $ 2^{CC(f)}$ rectangles.
$$\square$$This already gives us a bunch of theorems. Take the EQ function, for example. Its matrix is the identity matrix, and it’s not hard to see that every monochromatic tiling requires $ 2^n$ rectangles, one for each entry of the diagonal. I.e., $ CC(EQ) \geq n$. But we already know that one player can just send all his bits, so actually $ CC(EQ) = \Theta(n)$. Now it’s not always so easy to compute $ \chi(f)$. The impressive thing to do is to use efficiently computable information about $ M(f)$ to give bounds on $ \chi(f)$ and hence on $ CC(f)$. So can we come up with a better lower bound that depends on something we can compute? The answer is yes.
Theorem: For every function $ f$, $ \chi(f) \geq \textup{rank }M(f)$.
Proof. This just takes some basic linear algebra. One way to think of the rank of a matrix $ A$ is as the smallest way to write $ A$ as a linear combination of rank 1 matrices (smallest as in, the smallest number of terms needed to do this). The theorem is true no matter which field you use to compute the rank, although in this proof and in the rest of this post we’ll use the real numbers.
If you give me a monochromatic tiling by rectangles, I can view each rectangle as a matrix whose rank is at most one. If the entries are all zeros then the rank is zero, and if the entries are all ones then (using zero elsewhere) this is by itself a rank 1 matrix. So adding up these rectangles as separate components gives me an upper bound on the rank of $ A$. So the minimum way to do this is also an upper bound on the rank of $ A$.
$$\square$$Now computing something like $ CC(EQ)$ is even easier, because the rank of $ M(EQ) = M(I_{2^n})$ is just $ 2^n$.
Upper Bounds
There are other techniques to show lower bounds that are stronger than the rank and tiling method (because they imply the rank and tiling method). But I want to discuss upper bounds a bit, because the central open conjecture in communication complexity is an upper bound.
The Log-Rank Conjecture: There is a universal constant $ c$, such that for all $ f$, the communication complexity $ CC(f) = O((\log \textup{rank }M(f))^c)$.
All known examples satisfy the conjecture, but unfortunately the farthest progress toward the conjecture is still exponentially worse than the conjecture’s statement. In 1997 the record was due to Andrei Kotlov who proved that $ CC(f) \leq \log(4/3) \textup{rank }M(f)$. It was not until 2013 that any (unconditional) improvements were made to this, when Shachar Lovett proved that $ CC(f) = O(\sqrt{\textup{rank }M(f)} \cdot \log \textup{rank }M(f))$.
The interested reader can check out this survey of Shachar Lovett from earlier this year (2014) for detailed proofs of these theorems and a discussion of the methods. I will just discuss one idea from this area that ties in nicely with our discussion: which is that finding an efficient communication protocol for a low-rank function $ f$ reduces to finding a large monochromatic rectangle in $ M(f)$.
Theorem [Nisan-Wigderson 94]: Let $ c(r)$ be a function. Suppose that for any function $ f: X \times Y \to \{ 0,1 \}$, we can find a monochromatic rectangle of size $ R \geq 2^{-c(r)} \cdot | X \times Y |$ where $ r = \textup{rank }M(f)$. Then any such $ f$ is computable by a deterministic protocol with communication complexity.
$$\displaystyle O \left ( \log^2(r) + \sum_{i=0}^{\log r} c(r/2^i) \right )$$Just to be concrete, this says that if $ c(r)$ is polylogarithmic, then finding these big rectangles implies a protocol also with polylogarithmic complexity. Since the complexity of the protocol is a function of $ r$ alone, the log-rank conjecture follows as a consequence. The best known results use the theorem for larger $ c(r) = r^b$ for some $ b < 1$, which gives communication complexity also $ O(r^b)$.
The proof of the theorem is detailed, but mostly what you’d expect. You take your function, split it up into the big monochromatic rectangle and the other three parts. Then you argue that when you recurse to one of the other three parts, either the rank is cut in half, or the size of the matrix is much smaller. In either case, you can apply the theorem once again. Then you bound the number of leaves in the resulting protocol tree by looking at each level $ i$ where the rank has dropped to $ r/2^i$. For the full details, see page 4 of the Shachar survey.
Multiple Players and More
In the future we’ll cover some applications of communication complexity, many of which are related to computing in restricted models such as parallel computation and streaming computation. For example, in parallel computing you often have processors which get arbitrary chunks of data as input and need to jointly compute something. Lower bounds on the communication complexity can help you prove they require a certain amount of communication in order to do that.
But in these models there are many players. And the type of communication matters: it can be point-to-point or broadcast, or something more exotic like MapReduce. So before we can get to these applications we need to define and study the appropriate generalizations of communication complexity to multiple interacting parties.
Until then!
Want to respond? Send me an email, post a webmention, or find me elsewhere on the internet.