The singular value decomposition (SVD) of a matrix is a fundamental tool in computer science, data analysis, and statistics. It’s used for all kinds of applications from regression to prediction, to finding approximate solutions to optimization problems. In this series of two posts we’ll motivate, define, compute, and use the singular value decomposition to analyze some data. (Jump to the second post)
I want to spend the first post entirely on motivation and background. As part of this, I think we need a little reminder about how linear algebra equivocates linear subspaces and matrices. I say “I think” because what I’m going to say seems rarely spelled out in detail. Indeed, I was confused myself when I first started to read about linear algebra applied to algorithms, machine learning, and data science, despite having a solid understanding of linear algebra from a mathematical perspective. The concern is the connection between matrices as transformations and matrices as a “convenient” way to organize data.
Data vs. maps
Linear algebra aficionados like to express deep facts via statements about matrix factorization. That is, they’ll say something opaque like (and this is the complete statement for SVD we’ll get to in the post):
The SVD of an $ m \times n$ matrix $ A$ with real values is a factorization of $ A$ as $ U\Sigma V^T$, where $ U$ is an $ m \times m$ orthogonal matrix, $ V$ is an $ n \times n$ orthogonal matrix, and $ \Sigma$ is a diagonal matrix with nonnegative real entries on the diagonal.
Okay, I can understand the words individually, but what does it mean in terms of the big picture? There are two seemingly conflicting interpretations of matrices that muddle our vision.
The first is that $ A$ is a linear map from some $ n$-dimensional vector space to an $ m$-dimensional one. Let’s work with real numbers and call the domain vector space $ \mathbb{R}^n$ and the codomain $ \mathbb{R}^m$. In this interpretation the factorization expresses a change of basis in the domain and codomain. Specifically, $ V$ expresses a change of basis from the usual basis of $ \mathbb{R}^n$ to some other basis, and $ U$ does the same for the co-domain $ \mathbb{R}^m$.
That’s fine and dandy, so long as the data that makes up $ A$ is the description of some linear map we’d like to learn more about. Years ago on this blog we did exactly this analysis of a linear map modeling a random walk through the internet, and we ended up with Google’s PageRank algorithm. However, in most linear algebra applications $ A$ actually contains data in its rows or columns. That’s the second interpretation. That is, each row of $ A$ is a data point in $ \mathbb{R}^n$, and there are $ m$ total data points, and they represent observations of some process happening in the world. The data points are like people rating movies or weather sensors measuring wind and temperature. If you’re not indoctrinated with the linear algebra world view, you might not naturally think of this as a mapping of vectors from one vector space to another.
Most of the time when people talk about linear algebra (even mathematicians), they’ll stick entirely to the linear map perspective or the data perspective, which is kind of frustrating when you’re learning it for the first time. It seems like the data perspective is just a tidy convenience, that it just “makes sense” to put some data in a table. In my experience the singular value decomposition is the first time that the two perspectives collide, and (at least in my case) it comes with cognitive dissonance.
The way these two ideas combine is that the data is thought of as the image of the basis vectors of $ \mathbb{R}^n$ under the linear map specified by $ A$. Here is an example to make this concrete. Let’s say I want to express people rating movies. Each row will correspond to the ratings of a movie, and each column will correspond to a person, and the $ i,j$ entry of the matrix $ A$ is the rating person $ j$ gives to movie $ i$.
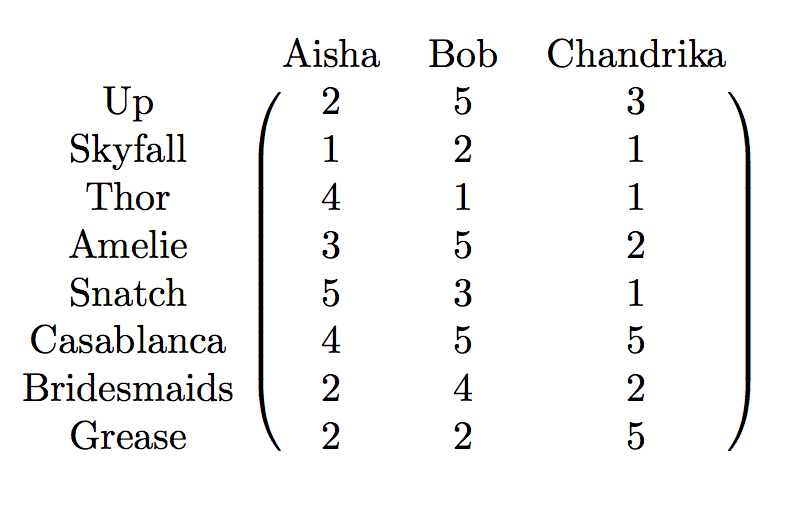
In reality they’re rated on a scale from 1 to 5 stars, but to keep things simple we’ll just say that the ratings can be any real numbers (they just happened to pick integers). So this matrix represents a linear map. The domain is $ \mathbb{R}^3$, and the basis vectors are called people, and the codomain is $ \mathbb{R}^8$, whose basis vectors are movies.
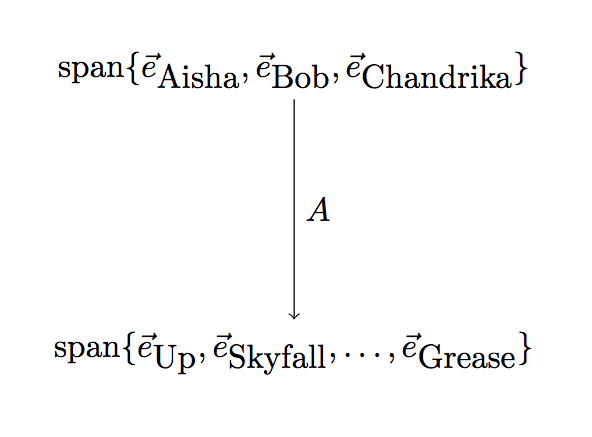
Now the data set is represented by $ A(\vec e_{\textup{Aisha}}),A(\vec e_{\textup{Bob}}),A(\vec e_{\textup{Chandrika}})$, and by the definition of how a matrix represents a linear map, the entires of these vectors are exactly the columns of $ A$. If the codomain is really big, then the image of $ A$ is a small-dimensional linear subspace of the codomain. This is an important step, that we’ve increased our view from just the individual data points to all of their linear combinations as a subspace.
Why is this helpful at all? This is where we start to see the modeling assumptions of linear algebra show through. If we’re trying to use this matrix to say something about how people rate movies (maybe we want to predict how a new person will rate these movies), we would need to be able to represent that person as a linear combination of Aisha, Bob, and Chandrika. Likewise, if we had a new movie and we wanted to use this matrix to say anything about it, we’d have to represent the movie as a linear combination of the existing movies.
Of course, I don’t literally mean that a movie (as in, the bits comprising a file containing a movie) can be represented as a linear combination of other movies. I mean that we can represent a movie formally as a linear combination in some abstract vector space for the task at hand. In other words, we’re representing those features of the movie that influence its rating abstractly as a vector. We don’t have a legitimate mathematical way to understand that, so the vector is a proxy.
It’s totally unclear what this means in terms of real life, except that you can hope (or hypothesize, or verify), that if the rating process of movies is “linear” in nature then this formal representation will accurately reflect the real world. It’s like how physicists all secretly know that mathematics doesn’t literally dictate the laws of nature, because humans made up math in their heads and if you poke nature too hard the math breaks down, but it’s so damn convenient to describe hypotheses (and so damn accurate), that we can’t avoid using it to design airplanes. And we haven’t found anything better than math for this purpose.
Likewise, movie ratings aren’t literally a linear map, but if we pretend they are we can make algorithms that predict how people rate movies with pretty good accuracy. So if you know that Skyfall gets ratings 1,2, and 1 from Aisha, Bob, and Chandrika, respectively, then a new person would rate Skyfall based on a linear combination of how well they align with these three people. In other words, up to a linear combination, in this example Aisha, Bob, and Chandrika epitomize the process of rating movies.
And now we get to the key: factoring the matrix via SVD provides an alternative and more useful way to represent the process of people rating movies. By changing the basis of one or both vector spaces involved, we isolate the different (orthogonal) characteristics of the process. In the context of our movie example, “factorization” means the following:
- Come up with a special list of vectors $ v_1, v_2, \dots, v_8$ so that every movie can be written as a linear combination of the $ v_i$.
- Do the analogous thing for people to get $ p_1, p_2, p_3$.
- Do (1) and (2) in such a way that the map $ A$ is diagonal with respect to both new bases simultaneously.
One might think of the $ v_i$ as “idealized movies” and the $ p_j$ as “idealized critics.” If you want to use this data to say things about the world, you’d be making the assumption that any person can be written as a linear combination of the $ p_j$ and any movie can be written as a linear combination of the $ v_i$. These are the rows/columns of $ U, V$ from the factorization. To reiterate, these linear combinations are only with respect to the task of rating movies. And they’re “special” because they make the matrix diagonal.
If the world was logical (and I’m not saying it is) then maybe $ v_1$ would correspond to some idealized notion of “action movie,” and $ p_1$ would correspond to some idealized notion of “action movie lover.” Then it makes sense why the mapping would be diagonal in this basis: an action movie lover only loves action movies, so $ p_1$ gives a rating of zero to everything except $ v_1$. A movie is represented by how it decomposes (linearly) into “idealized” movies. To make up some arbitrary numbers, maybe Skyfall is 2/3 action movie, 1/5 dystopian sci-fi, and -6/7 comedic romance. Likewise a person would be represented by how they decompose (via linear combination) into a action movie lover, rom-com lover, etc.
To be completely clear, the singular value decomposition does not find the ideal sci-fi movie. The “ideal”ness of the singular value decomposition is with respect to the inherent geometric structure of the data coupled with the assumptions of linearity. Whether this has anything at all to do with how humans classify movies is a separate question, and the answer is almost certainly no.
With this perspective we’re almost ready to talk about the singular value decomposition. I just want to take a moment to write down a list of the assumptions that we’d need if we want to ensure that, given a data set of movie ratings, we can use linear algebra to make exact claims about world.
- All people rate movies via the same linear map.
- Every person can be expressed (for the sole purpose of movie ratings) as linear combinations of “ideal” people. Likewise for movies.
- The “idealized” movies and people can be expressed as linear combinations of the movies/people in our particular data set.
- There are no errors in the ratings.
One could have a deep and interesting discussion about the philosophical (or ethical, or cultural) aspects of these assumptions. But since the internet prefers to watch respectful discourse burn, we’ll turn to algorithms instead.
Approximating subspaces
In our present context, the singular value decomposition (SVD) isn’t meant to be a complete description of a mapping in a new basis, as we said above. Rather, we want to use it to approximate the mapping $ A$ by low-dimensional linear things. When I say “low-dimensional linear things” I mean that given $ A$, we’d want to find another matrix $ B$ which is measurably similar to $ A$ in some way, and has low rank compared to $ A$.
How do we know that $ A$ isn’t already low rank? The reasons is that data with even the tiniest bit of noise is full rank with overwhelming probability. A concrete way to say this is that the space of low-rank matrices has small dimension (in the sense of a manifold) inside the space of all matrices. So perturbing even a single entry by an infinitesimally small amount would increase the rank.
We don’t need to understand manifolds to understand the SVD, though. For our example of people rating movies the full-rank property should be obvious. The noise and randomness and arbitrariness in human preferences certainly destroys any “perfect” linear structure we could hope to find, and in particular that means the data set itself, i.e. the image of $ A$, is a large-dimensional subspace of the codomain.
Finding a low-rank approximation can be thought of as “smoothing” the noise out of the data. And this works particularly well when the underlying process is close to a linear map. That is, when the data is close to being contained entirely in a single subspace of relatively low-dimension. One way to think of why this might be the case is that if the process you’re observing is truly linear, but the data you get is corrupted by small amounts of noise. Then $ A$ will be close to low rank in a measurable sense (to be defined mathematically in the sequel post) and the low-rank approximation $ B$ will be a more efficient, accurate, and generalizable surrogate for $ A$.
In terms of our earlier list of assumptions about when you can linear algebra to solve problems, for the SVD we can add “approximately” to the first three assumptions, and “not too many errors” to the fourth. If those assumptions hold, SVD will give us a matrix $ B$ which accurately represents the process being measured. Conversely, if SVD does well, then you have some evidence that the process is linear-esque.
To be more specific with notation, if $ A$ is a matrix representing some dataset via the image of $ A$ and you provide a small integer $ k$, then the singular value decomposition computes the rank $ k$ matrix $ B_k$ which best approximates $ A$. And since now we’re comfortable identifying a data matrix with the subspace defined by its image, this is the same thing as finding the $ k$-dimensional subspace of the image of $ A$ which is the best approximation of the data (i.e., the image of $ B_k$). We’ll quantify what we mean by “best approximation” in the next post.
That’s it, as far as intuitively understanding what the SVD is. I should add that the SVD doesn’t only allow one to compute a rank $ k$ approximation, it actually allows you to set $ k=n$ and get an exact representation of $ A$. We just won’t use it for that purpose in this series.
The second bit of intuition is the following. It’s only slightly closer to rigor, but somehow this little insight really made SVD click for me personally:
The SVD is what you get when you iteratively solve the greedy optimization problem of fitting data to a line.
By that I mean, you can compute the SVD by doing the following:
- What’s the best line fitting my data?
- Okay, ignoring that first line, what’s the next best line?
- Okay, ignoring all the lines in the span of those first two lines, what’s the next best line?
- Ignoring all the lines in the span of the first three lines, what’s the next best line?
- (repeat)
It should be shocking that this works. For most problems, in math and in life, the greedy algorithm is far from optimal. When it happens, once every blue moon, that the greedy algorithm is the best solution to a natural problem (and not obviously so, or just approximately so), it’s our intellectual duty to stop what we’re doing, sit up straight, and really understand and appreciate it. These wonders transcend political squabbles and sports scores. And we’ll start the next post immediately by diving into this greedy optimization problem.
The geometric perspective
There are two other perspectives I want to discuss here, though it may be more appropriate for a reader who is not familiar with the SVD to wait to read this after the sequel to this post. I’m just going to relate my understanding (in terms of the greedy algorithm and data approximations) to the geometric and statistical perspectives on the SVD.
Michael Nielsen wrote a long and detailed article presenting some ideas about a “new medium” in which to think about mathematics. He demonstrates is framework by looking at the singular value decomposition for 2×2 matrices. His explanation for the intuition behind the SVD is that you can take any matrix (linear map) and break it up into three pieces: a rotation about the origin, a rescaling of each coordinate, followed by another rotation about the origin. While I have the utmost respect for Nielsen (his book on quantum mechanics is the best text in the field), this explanation never quite made SVD click for me personally. It seems like a restatement of the opaque SVD definition (as a matrix factorization) into geometric terms. Indeed, an orthogonal matrix is a rotation, and a diagonal matrix is a rescaling of each coordinate.
To me, the key that’s missing from this explanation is the emphasis on the approximation. What makes the SVD so magical isn’t that the factorization exists in the first place, but rather that the SVD has these layers of increasingly good approximation. Though the terminology will come in the next post, these layers are the (ordered) singular vectors and singular values. And moreover, that the algorithmic process of constructing these layers necessarily goes in order from strongest approximation to weakest.
Another geometric perspective that highlights this is that the rank-$ k$ approximation provided by the SVD is a geometric projection of a matrix onto the space of rank at-most-k matrices with respect to the “spectral norm” on matrices (the spectral norm of $ A$ is the largest eigenvalue of $ A^TA$). The change of basis described above makes this projection very easy: given a singular value decomposition you just take the top $ k$ singular vectors. Indeed, the Eckart-Young theorem formalizes this with the statement that the rank-$ k$ SVD $ B_k$ minimizes the distance (w.r.t. the spectral norm) between the original matrix $ A$ and any rank $ k$ matrix. So you can prove that SVD gives you the best rank $ k$ approximation of $ A$ by some reasonable measure.
Next time: algorithms
Next time we’ll connect all this to the formal definitions and rigor. We’ll study the greedy algorithm approach, and then we’ll implement the SVD and test it on some data.
Until then!
Want to respond? Send me an email, post a webmention, or find me elsewhere on the internet.