Some mathy-programmy people tell me they want to test their code, but struggle to get set up with a testing framework. I suspect it’s due to a mix of:
- There are too many choices with a blank slate.
- Making slightly wrong choices early on causes things to fail in unexpected ways.
I suspect the same concerns apply to general project organization and architecture. Because Python is popular for mathy-programmies, I’ll build a Python project that shows how I organize my projects and and test my code, and how that shapes the design and evolution of my software. I will use Python 3.8 and pytest, and you can find the final code on Github.
For this project, we’ll take advice from John Baez and explore a question that glibly aims to disprove the Riemann Hypothesis:
A CHALLENGE:
Let σ(n) be the sum of divisors of n. There are infinitely many n with σ(n)/(n ln(ln(n)) > 1.781. Can you find one? If you can find n > 5040 with σ(n)/(n ln(ln(n)) > 1.782, you’ll have disproved the Riemann Hypothesis.
I don’t expect you can disprove the Riemann Hypothesis this way, but I’d like to see numbers that make σ(n)/(n ln(ln(n)) big. It seems the winners are all multiples of 2520, so try those. The best one between 5040 and a million is n = 10080, which only gives 1.755814.
https://twitter.com/johncarlosbaez/status/1149700802371608576
Initializing the Project
One of the hardest parts of software is setting up your coding environment. If you use an integrated development environment (IDE), project setup is bespoke to each IDE. I dislike this approach, because what you learn when using the IDE is not useful outside the IDE. When I first learned to program (Java), I was shackled to Eclipse for years because I didn’t know how to compile and run Java programs without it. Instead, we’ll do everything from scratch, using only the terminal/shell and standard Python tools. I will also ignore random extra steps and minutiae I’ve built up over the years to deal with minor issues. If you’re interested in that and why I do them, leave a comment and I might follow up with a second article.
This article assumes you are familiar with the basics of Python syntax, and know how to open a terminal and enter basic commands (like ls, cd, mkdir, rm). Along the way, I will link to specific git commits that show the changes, so that you can see how the project unfolds with each twist and turn.
I’ll start by creating a fresh Python project that does nothing. We set up the base directory riemann-divisor-sum, initialize git, create a readme, and track it in git (git add + git commit).
mkdir riemann-divisor-sum
cd riemann-divisor-sum
git init .
echo "# Divisor Sums for the Riemann Hypothesis" > README.md
git add README.md
git commit -m "add empty README.md"
Next I create a Github project at https://github.com/j2kun/riemann-divisor-sum (the name riemann-divisor-sum does not need to be the same, but I think it’s good), and push the project up to Github.
git remote add origin git@github.com:j2kun/riemann-divisor-sum.git
# instead of "master", my default branch is really "main"
git push -u origin master
Note, if you’re a new Github user, the “default branch name” when creating a new project may be “master.” I like “main” because it’s shorter, clearer, and nicer. If you want to change your default branch name, you can update to git version 2.28 and add the following to your ~/.gitconfig file.
[init]
defaultBranch = main
Here is what the project looks like on Github as of this single commit.
Pytest
Next I’ll install the pytest library which will run our project’s tests. First I’ll show what a failing test looks like, by setting up a trivial program with an un-implemented function, and a corresponding test. For ultimate simplicity, we’ll use Python’s built-in assert for the test lines. Here’s the commit.
# in the terminal
mkdir riemann
mkdir tests
# create riemann/divisor.py containing:
'''Compute the sum of divisors of a number.'''
def divisor_sum(n: int) -> int:
raise ValueError("Not implemented.")
# create tests/divisor_test.py containing:
from riemann.divisor import divisor_sum
def test_sum_of_divisors_of_72():
assert 195 == divisor_sum(72)
Next we install and configure Pytest. At this point, since we’re introducing a dependency, we need a project-specific place to store that dependency. All dependencies related to a project should be explicitly declared and isolated. This page helps explain why. Python’s standard tool is the virtual environment. When you “activate” the virtual environment, it temporarily (for the duration of the shell session or until you run deactivate) points all Python tools and libraries to the virtual environment.
virtualenv -p python3.8 venv
source venv/bin/activate
# shows the location of the overridden python binary path
which python
# outputs: /Users/jeremy/riemann-divisor-sum/venv/bin/python
Now we can use pip as normal and it will install to venv. To declare and isolate the dependency, we write the output of pip freeze to a file called requirements.txt, and it can be reinstalled using pip install -r requirements.txt. Try deleting your venv directory, recreating it, and reinstalling the dependencies this way.
pip install pytest
pip freeze > requirements.txt
git add requirements.txt
git commit -m "requirements: add pytest"
# example to wipe and reinstall
# deactivate
# rm -rf venv
# virtualenv -p python3.8 venv
# source venv/bin/activate
# pip install -r requirements.txt
As an aside, at this step you may notice git mentions venv is an untracked directory. You can ignore this, or add venv to a .gitignore file to tell git to ignore it, as in this commit. We will also have to configure pytest to ignore venv shortly.
When we run pytest (with no arguments) from the base directory, we see our first error:
from riemann.divisor import divisor_sum
E ModuleNotFoundError: No module named 'riemann'
Module import issues are a common stumbling block for new Python users. In order to make a directory into a Python module, it needs an __init__.py file, even if it’s empty. Any code in this file will be run the first time the module is imported in a Python runtime. We add one to both the code and test directories in this commit.
When we run pytest (with no arguments), it recursively searches the directory tree looking for files like *test.py and test*.py loads them, and treats every method inside those files that are prefixed with “test” as a test. Non-“test” methods can be defined and used as helpers to set up complex tests. Pytest then runs the tests, and reports the failures. For me this looks like
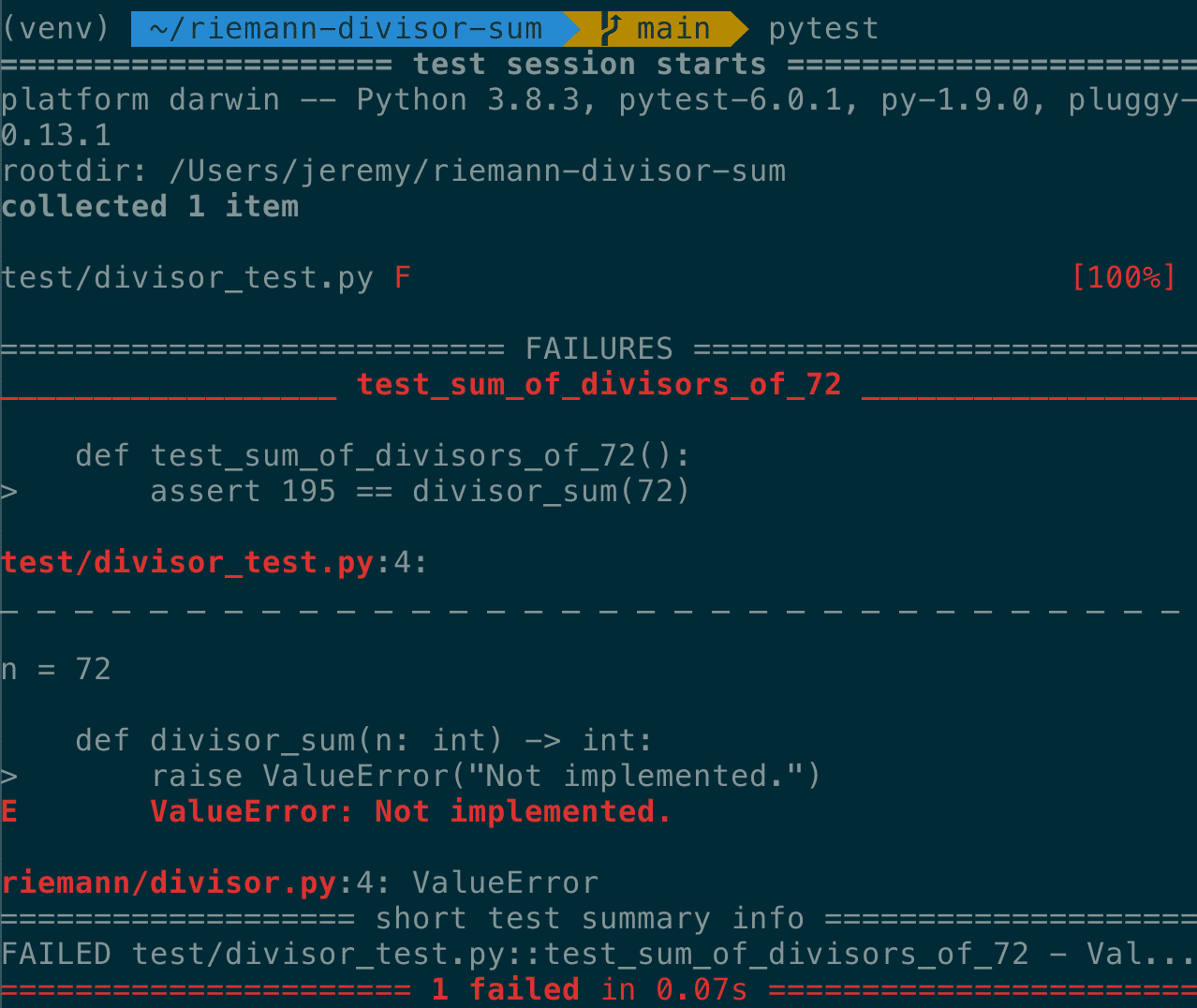
Our first test failure.
Our implementation is intentionally wrong for demonstration purposes. When a test passes, pytest will report it quietly as a “.” by default. See these docs for more info on different ways to run the pytest binary and configure its output report.
In this basic pytest setup, you can put test files wherever you want, name the files and test methods appropriately, and use assert to implement the tests themselves. As long as your modules are set up properly, as long as imports are absolute (see this page for gory details on absolute vs. relative imports), and as long as you run pytest from the base directory, pytest will find the tests and run them.
Since pytest searches all directories for tests, this includes venv and __pycache__, which magically appears when you create python modules (I add __pycache__ to gitignore). Sometimes package developers will include test code, and pytest will then run those tests, which often fail or clutter the output. A virtual environment also gets large as you install big dependencies (like numpy, scipy, pandas), so this makes pytest slow to search for tests to run. To alleviate, the --norecursedirs command line flag tells pytest to skip directories. Since it’s tedious to type --norecursedirs='venv __pycache__' every time you run pytest, you can make this the default behavior by storing the option in a configuration file recognized by pytest, such as setup.cfg. I did it in this commit.
Some other command line options that I use all the time:
pytest test/dirto test only files in that directory, orpytest test/dir/test_file.pyto test only tests in that file.pytest -k STRto only run tests whose name contains “STR”pytest -sto see see any logs or print statements inside tested codepytest -sto allow the pdb/ipdb debugger to function and step through a failing test.
Building up the project
Now let’s build up the project. My general flow is as follows:
- Decide what work to do next.
- Sketch out the interface for that work.
- Write some basic (failing, usually lightweight) tests that will pass when the work is done.
- Do the work.
- Add more nuanced tests if needed, based on what is learned during the work.
- Repeat until the work is done.
This strategy is sometimes called “the design recipe,” and I first heard about it from my undergraduate programming professor John Clements at Cal Poly, via the book “How to Design Programs.” Even if I don’t always use it, I find it’s a useful mental framework for getting things done.
For this project, I want to search through positive integers, and for each one I want to compute a divisor sum, do some other arithmetic, and compare that against some other number. I suspect divisor sum computations will be the hard/interesting part, but to start I will code up a slow/naive implementation with some working tests, confirm my understanding of the end-to-end problem, and then improve the pieces as needed.
In this commit, I implement the naive divisor sum code and tests. Note the commit also shows how to tell pytest to test for a raised exception. In this commit I implement the main search routine and confirm John’s claim about $ n=10080$ (thanks for the test case!).
These tests already showcase a few testing best practices:
- Test only one behavior at a time. Each test has exactly one assertion in it. This is good practice because when a test fails you won’t have to dig around to figure out exactly what went wrong.
- Use the tests to help you define the interface, and then only test against that interface. The hard part about writing clean and clear software is defining clean and clear interfaces that work together well and hide details. Math does this very well, because definitions like $ \sigma(n)$ do not depend on how $ n$ is represented. In fact, math really doesn’t have “representations” of its objects—or more precisely, switching representations is basically free, so we don’t dwell on it. In software, we have to choose excruciatingly detailed representations for everything, and so we rely on the software to hide those details as much as possible. The easiest way to tell if you did it well is to try to use the interface and only the interface, and tests are an excuse to do that, which is not wasted effort by virtue of being run to check your work.
Improving Efficiency
Next, I want to confirm John’s claim that $ n=10080$ is the best example between 5041 and a million. However, my existing code is too slow. Running the tests added in this commit seems to take forever.
We profile to confirm our suspected hotspot:
>>> import cProfile
>>> from riemann.counterexample_search import best_witness
>>> cProfile.run('best_witness(10000)')
ncalls tottime percall cumtime percall filename:lineno(function)
...
54826 3.669 0.000 3.669 0.000 divisor.py:10(<genexpr>)
As expected, computing divisor sums is the bottleneck. No surprise there because it makes the search take quadratic time. Before changing the implementation, I want to add a few more tests. I copied data for the first 50 integers from OEIS and used pytest’s parameterize feature since the test bodies are all the same. This commit does it.
Now I can work on improving the runtime of the divisor sum computation step. Originally, I thought I’d have to compute the prime factorization to use this trick that exploits the multiplicativity of $ \sigma(n)$, but then I found this approach due to Euler in 1751 that provides a recursive formula for the sum and skips the prime factorization. Since we’re searching over all integers, this allows us to trade off the runtime of each $ \sigma(n)$ computation against the storage cost of past $ \sigma(n)$ computations. I tried it in this commit, using python’s built-in LRU-cache wrapper to memoize the computation. The nice thing about this is that our tests are already there, and the interface for divisor_sum doesn’t change. This is on purpose, so that the caller of divisor_sum (in this case tests, also client code in real life) need not update when we improve the implementation. I also ran into a couple of stumbling blocks implementing the algorithm (I swapped the order of the if statements here), and the tests made it clear I messed up.
However, there are two major problems with that implementation.
- The code is still too slow.
best_witness(100000)takes about 50 seconds to run, almost all of which is indivisor_sum. - Python hits its recursion depth limit, and so the client code needs to eagerly populate the
divisor_sumcache, which is violates encapsulation. The caller should not know anything about the implementation, nor need to act in a specific way to accommodate hidden implementation details.
I also realized after implementing it that despite the extra storage space, the runtime is still $ O(n^{3/2})$, because each divisor-sum call requires $ O(n^{1/2})$ iterations of the loop. This is just as slow as a naive loop that checks divisibility of integers up to $ \sqrt{n}$. Also, a naive loop allows me to plug in a cool project called numba that automatically speeds up simple Python code by compiling it in place. Incidentally, numba is known to not work with lru_cache, so I can’t tack it on my existing implementation.
So I added numba as a dependency and drastically simplified the implementation. Now the tests run in 8 seconds, and in a few minutes I can upgrade John’s claim that $ n=10080$ is the best example between 5041 and a million, to the best example between 5041 and ten million.
Next up
This should get you started with a solid pytest setup for your own project, but there is a lot more to say about how to organize and run tests, what kinds of tests to write, and how that all changes as your project evolves.
For this project, we now know that the divisor-sum computation is the bottleneck. We also know that the interesting parts of this project are yet to come. We want to explore the patterns in what makes these numbers large. One way we could go about this is to split the project into two components: one that builds/manages a database of divisor sums, and another that analyzes the divisor sums in various ways. The next article will show how the database set up works. When we identify relevant patterns, we can modify the search strategy to optimize for that. As far as testing goes, this would prompt us to have an interface layer between the two systems, and to add fakes or mocks to test the components in isolation.
After that, there’s the process of automating test running, adding tests for code quality/style, computing code coverage, adding a type-hint checker test, writing tests that generate other tests, etc.
If you’re interested, let me know which topics to continue with. I do feel a bit silly putting so much pomp and circumstance around such a simple computation, but hopefully the simplicity of the core logic makes the design and testing aspects of the project clearer and easier to understand.
Want to respond? Send me an email, post a webmention, or find me elsewhere on the internet.