We’re ironically searching for counterexamples to the Riemann Hypothesis.
In the last article we ran into some performance issues with our deployed docker application. In this article we’ll dig in to see what happened, fix the problem, run into another problem, fix it, and run the search until we rule out RH witness-value-based counterexamples among all numbers with fewer than 85 prime factors.
When debugging any issue, there are some straightforward steps to follow.
- Gather information to determine where the problem is.
- Narrow down the source of the problem.
- Reproduce the problem in an isolated environment (on your local machine or a separate EC2 instance).
- Fix the problem.
So far what I know is that the search ran for days on EC2 with docker, and didn’t make significantly more progress than when I ran it on my local machine for a few hours.
Gathering information
Gathering information first is an important step that’s easy to skip when you think you know the problem. In my experience, spending an extra 5-10 minutes just looking around can save hours of work you might spend fixing the wrong problem.
So we know the application is slow. But there are many different kinds of slow. We could be using up all the CPU, running low on free RAM, throttled by network speeds, and more. To narrow down which of these might be the problem, we can look at the server’s resource usage.
The CPU utilization EC2 dashboard below shows that after just a few hours of running the application, the average CPU utilization drops to 5-10% and stays at that level. Running docker stats shows that the search container has over 5 GiB of unused RAM. df -h shows that the server has more than 60% of its disk space free.
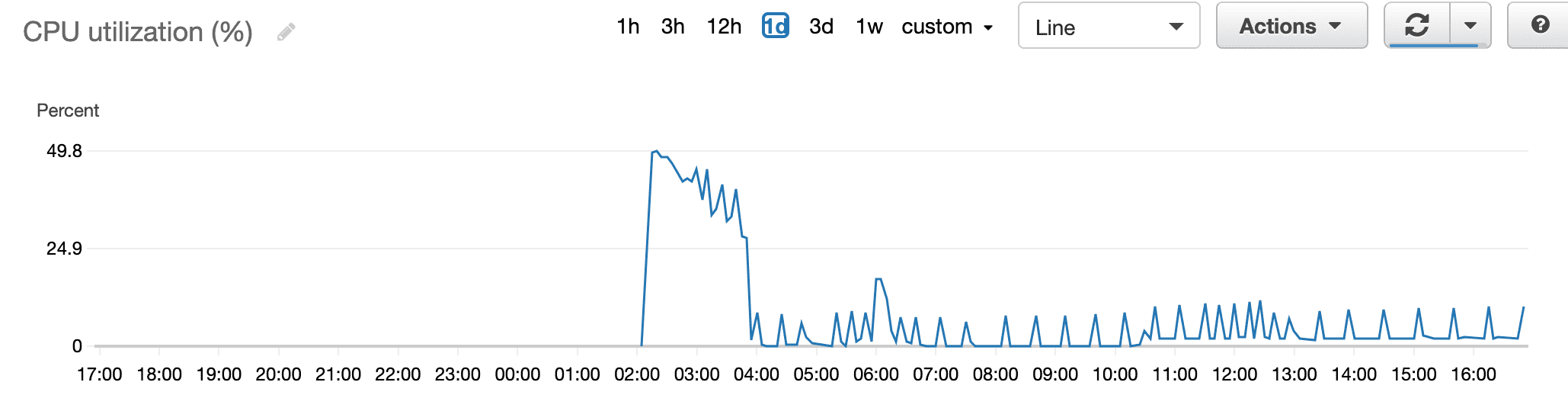
The fact that the CPU spikes like this suggests that the program is doing its work, just with gaps in between the real work, and some sort of waiting consuming the rest of the time.
Another angle we can look at is the timestamps recorded in the SearchMetadata table.
divisor=# select * from searchmetadata order by start_time desc limit 9;
start_time | end_time | search_state_type | starting_search_state | ending_search_state
----------------------------+----------------------------+-------------------------------+-----------------------+---------------------
2021-01-01 15:40:42.374536 | 2021-01-01 16:15:34.838774 | SuperabundantEnumerationIndex | 71,1696047 | 71,1946047
2021-01-01 15:06:13.947216 | 2021-01-01 15:40:42.313078 | SuperabundantEnumerationIndex | 71,1446047 | 71,1696047
2021-01-01 14:32:14.692185 | 2021-01-01 15:06:13.880209 | SuperabundantEnumerationIndex | 71,1196047 | 71,1446047
2021-01-01 13:57:39.725843 | 2021-01-01 14:32:14.635433 | SuperabundantEnumerationIndex | 71,946047 | 71,1196047
2021-01-01 13:25:53.376243 | 2021-01-01 13:57:39.615891 | SuperabundantEnumerationIndex | 71,696047 | 71,946047
2021-01-01 12:59:14.58666 | 2021-01-01 13:25:53.331857 | SuperabundantEnumerationIndex | 71,446047 | 71,696047
2021-01-01 12:43:08.503441 | 2021-01-01 12:59:14.541995 | SuperabundantEnumerationIndex | 71,196047 | 71,446047
2021-01-01 12:27:49.698012 | 2021-01-01 12:43:08.450301 | SuperabundantEnumerationIndex | 70,4034015 | 71,196047
2021-01-01 12:14:44.970486 | 2021-01-01 12:27:49.625687 | SuperabundantEnumerationIndex | 70,3784015 | 70,4034015
As you can see, computing a single block of divisor sums takes over a half hour in many cases! This is nice, because we can isolate the computation of a single block on our local machine and time it.
Narrowing Down
Generally, since we ran this application on a local machine just fine for longer than we ran it in docker on EC2, I would think the culprit is related to the new thing that was introduced: docker and/or EC2. My local machine is a Mac, and the EC2 machine was Ubuntu linux, so there could be a difference there. It’s also strange that the system only started to slow down after about two hours, instead of being slow the whole time. That suggests there is something wrong with scaling, i.e., what happens as the application starts to grow in its resource usage.
Just to rule out the possibility that it’s a problem with computing and storing large blocks, let’s re-test the block with starting index 71,196047 and ending index 71,446047, which took approximated 16 minutes on EC2. These three lines are between the start/end timestamps in the table. Only the second line does substantive work.
start_state = search_strategy.search_state()
db.upsert(search_strategy.next_batch(batch_size))
end_state = search_strategy.search_state()
First we’ll just run the next_batch method, to remove the database upsert from consideration. We’ll also do it in a vanilla Python script, to remove the possibility that docker is introducing inefficiency, which is the most likely culprit, since docker is the new part from the last article. This commit has the timing test and the result shows that on average the block takes two minutes on my local machine.
Running the same code in a docker container on EC2 has the same result, which I verified by copying the divisorsearch.Dockerfile to a new dockerfile and replacing the entrypoint command with
ENTRYPOINT ["python3", "-u", "-m", "timing.ec2_timing_test"]
Then running (on a fresh EC2 instance with docker installed and the repo cloned)
docker build -t timing -f timing.Dockerfile .
docker run -dit --name timing --memory="15G" --env PGHOST="$PGHOST" timing:latest
docker logs -f timing
Once it finishes, I see it takes on average 40 seconds to compute the block. So any prior belief that the divisor computation might be the bottleneck are now gone.
Now let’s try the call to db.upsert, which builds the query and sends it over the network to the database container. Testing that in isolation—by computing the block first and then timing the upsert with this commit —shows it takes about 8 seconds to update an empty database with this block.
Both of these experiments were run on EC2 in docker, so we’ve narrowed down the problem enough to say that it only happens when the system has been running for that two hour window. My best guess is something to do with having a large database, or something to do with container-to-container networking transfer rates (the docker overhead). The next step in narrowing down the problem is to set up the scenario and run performance profiling tools on the system in situ.
I spin back up an r5.large. Then I run the deploy script and wait for two hours. It started slowing down after about 1h45m of runtime. At this point I stopped the divisorsearch container and ran the timing test container. And indeed, the upsert step has a strangely slow pattern (the numbers are in seconds):
Running sample 0
55.63926291465759
Running sample 1
61.28182792663574
Running sample 2
245.36470413208008 # 4 minutes
Running sample 3
1683.663686990738 # 28 minutes
At this point I killed the timing test. The initial few writes, while not great, are not as concerning as the massive degradation in performance over four writes. At this point I’m convinced that the database is the problem. So I read a lot about Postgres performance tuning (e.g. these docs and this blog post), which I had never done before.
It appears that the way Postgres inserts work is by writing to a “write cache,” and then later a background process copies the content of the write cache to disk. This makes sense because disk writes are slow. But if the write cache is full, then Postgres will wait until the write cache gets emptied before it can continue. This seems likely here: the first few writes are fast, and then when the cache fills up later writes take eons.
I also learned that the PRIMARY KEY part of our Postgres schema incurs a penalty to write performance, because in order to enforce the uniqueness Postgres needs to maintain a data structure and update it on every write. I can imagine that, because an mpz (unbounded integer) is our primary key, that data structure might be unprepared to handle such large keys. This might explain why these writes are taking so long in the first place, given that each write itself is relatively small (~2 MiB). In our case we can probably get by without a primary key on this table, and instead put any uniqueness constraints needed on the search metadata table.
So let’s change one of these and see if it fixes the problem. First we can drop the primary key constraint, which we can do in situ by running the query
alter table riemanndivisorsums drop constraint divisor_sum_pk;
This query takes a long time, which seems like a good sign. Perhaps it’s deleting a lot of data. Once that’s done, I removed the ON CONFLICT clause from the upsert command (it becomes just an insert command), and then rebuild and re-run the timing container. This shows that each insert takes only 3-4 seconds, which is much more reasonable.
Running sample 0
3.8325071334838867
Running sample 1
3.7897982597351074
Running sample 2
3.7978150844573975
Running sample 3
3.810023784637451
Running sample 4
3.8057897090911865
I am still curious about the possible fix by increasing the cache size, but my guess is that without the primary key change, increasing the cache size would just delay the application from slowing instead of fixing the problem permanently, so for now I will not touch it. Perhaps a reader with more experience with Postgres tuning would know better.
Updating the application
So with this new understanding, how should we update the application? Will anything go wrong if we delete the primary key on the RiemannDivisorSums table?
As suggested by our need to remove the ON CONFLICT clause, we might end up with duplicate rows. That is low risk, but scarier is if we stop the search mid-block and restart it, then if we’re really unlucky, we might get into a state where we skip a block and don’t notice, and that block contains the unique counterexample to the Riemann Hypothesis! We simply can’t let that happen. This is far too important. To be fair, this is a risk even before we remove the primary key. I’m just realizing it now.
We’ll rearchitect the system to mitigate that in a future post, and it will double as providing a means to scale horizontally. For now, this pull request removes the primary key constraint and does a bit of superficial cleanup. Now let’s re-run it!
Out of RAM again
This time, it ran for three hours before the divisorsearch container hit the 15 GiB RAM limit and crashed. Restarting the container and watching docker stats showed that it plain ran out of RAM. This is a much easier problem to solve because it involves only one container, and the virtual machine doesn’t slow to a crawl when it occurs, the container just stops running.
A quick python memory profile reveals the top 10 memory usages by line, the top being search_strategy.py:119 clocking in at about 2.2 GiB.
from riemann.search_strategy import SuperabundantSearchStrategy
from riemann.types import SuperabundantEnumerationIndex
import tracemalloc
tracemalloc.start()
search_strategy = SuperabundantSearchStrategy().starting_from(
SuperabundantEnumerationIndex(71, 196047))
batch = search_strategy.next_batch(250000)
snapshot = tracemalloc.take_snapshot()
top_stats = snapshot.statistics('lineno')
print("[ Top 10 ]")
for stat in top_stats[:10]:
print(stat)
Results:
[ Top 10 ]
riemann/search_strategy.py:119: size=2245 MiB, count=9394253, average=251 B
venv/lib/python3.7/site-packages/llvmlite/ir/values.py:224: size=29.6 MiB, count=9224, average=3367 B
<string>:2: size=26.7 MiB, count=499846, average=56 B
riemann/superabundant.py:67: size=19.1 MiB, count=500003, average=40 B
riemann/superabundant.py:69: size=15.3 MiB, count=250000, average=64 B
riemann/superabundant.py:70: size=13.4 MiB, count=250000, average=56 B
venv/lib/python3.7/site-packages/llvmlite/ir/_utils.py:48: size=3491 KiB, count=6411, average=558 B
venv/lib/python3.7/site-packages/llvmlite/ir/values.py:215: size=2150 KiB, count=19267, average=114 B
riemann/search_strategy.py:109: size=2066 KiB, count=1, average=2066 KiB
venv/lib/python3.7/site-packages/llvmlite/ir/_utils.py:58: size=1135 KiB, count=2018, average=576 B
This line, not surprisingly, is the computation of the full list of partitions of $ n$. The length of this list grows superpolynomially in $ n$, which explains why it takes up all the RAM.
Since we only need to look at at most batch_size different partitions of $ n$ at a given time, we can probably fix this by adding a layer of indirection so that new sections of the partition list are generated on the fly and old sections are forgotten once the search strategy is done with them.
This pull request does that, and running the memory test again shows the 2.5 GiB line above reduced to 0.5 GiB. The pull request description also has some thoughts about the compute/memory tradeoff being made by this choice, and thoughts about how to improve the compute side.
So let’s run it again!! This time it runs for about 19 hours before crashing, as shown by the EC2 CPU usage metrics.
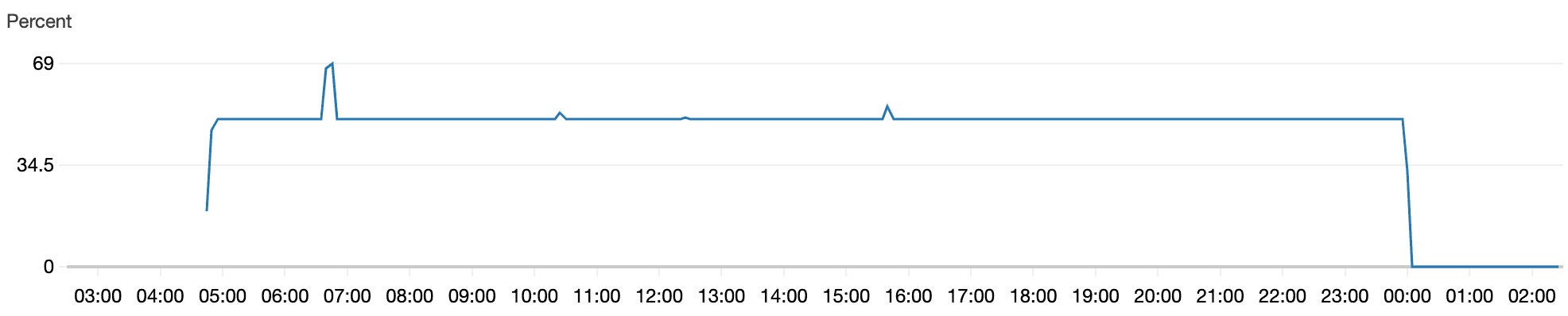
The application ran for about 19 hours before crashing.
According to the SearchMetadata table, we got up to part way through $ n=87$
divisor=# select * from searchmetadata order by start_time desc limit 3;
start_time | end_time | search_state_type | starting_search_state | ending_search_state
----------------------------+----------------------------+-------------------------------+-----------------------+---------------------
2021-01-27 00:00:11.59719 | 2021-01-27 00:01:14.709715 | SuperabundantEnumerationIndex | 87,15203332 | 87,15453332
2021-01-26 23:59:01.285508 | 2021-01-27 00:00:11.596075 | SuperabundantEnumerationIndex | 87,14953332 | 87,15203332
2021-01-26 23:57:59.809282 | 2021-01-26 23:59:01.284257 | SuperabundantEnumerationIndex | 87,14703332 | 87,14953332
Logging into the server and running df -h we can see the reason for the crash is that the disk is full. We filled up a 60 GiB SSD full of Riemann divisor sums. It’s quite an achievement. I’d like to thank my producers, the support staff, my mom, and the Academy.
But seriously, this is the best case scenario. Our limiting factor now is just how much we want to pay for disk space (and/or, any tricks we come up with to reduce disk space).
Analyzing the results, it seems we currently have 949 examples of numbers with witness values bigger than 1.767. Here are the top few:
n | divisor_sum | witness_value
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------
533187564151227457465199401229454876347036513892234205802944360099435118364718466037392872608220305945979716166395732328054742493039981726997486787797703088097204529280000 | 5634790045188254963919691913741193557789227457256740288527114259589826494137632464425981545755572664137227875215269764405574488353138596297944567958732800000000000000000000 | 1.7689901658397056
1392134632248635659178066321747923959130643639405311242305337754828812319490126543178571468950966856255821713228187290673772173611070448373361584302343872292681996160000 | 14673932409344413968540864358701024890076113169939427834706026717681839828483417876109326942071803812857364258373098344806183563419631761192563979059200000000000000000000 | 1.7688977455109272
3673178449204843427910465228886342900080853929829317262019360830682882109472629401526573796704398037614305311947723722094385682351109362462695473093255599716839040000 | 38615611603537931496160169365002697079147666236682704828173754520215367969693204937129807742294220560150958574666048275805746219525346739980431523840000000000000000000 | 1.7688303488154073
2784269264497271318356132643495847918261287278810622484610675509657624638980253086357142937901933712511643426456374581347544347222140896746723168604687744585363992320000 | 29355033324995298095346770663840105972086801871471400577978104254473441181064775868425839681379597759477726740614478613571725301516068423098949435392000000000000000000000 | 1.768798862584946
9847663402693950208875241900499578820592101688550448423644399009873678577674609655567221975078815114247467324256631962719532660458738237165403413118647720420480000 | 103250298405181635016471041082894911976330658386852151946988648449773711148912312666122480594369573690243204745096385764186487217982210534707036160000000000000000000 | 1.7687597437473672
The best so far achieves 1.76899. Recall out last best number achieved a witness value of 1.7679, a modest improvement if we hope to get to 1.82 (or even the supposedly infinitely many examples with witness value bigger than 1.81!).
What’s next?
We’re not stopping until we disprove the Riemann hypothesis. So strap in, this is going to be a long series.
Since the limiting factor in our search is currently storage space, I’d like to spend some time coming up with a means to avoid storing the witness value and divisor sum for every single number in our search strategy, but still maintain the ability to claim our result (no counterexamples below N) while providing the means for a skeptical person to verify our claims as much as they desire without also storing the entire search space on disk.
Once we free ourselves from disk space constraints, the second limiting factor is that our search uses only a single CPU at a time. We should rearchitect the system so that we can scale horizontally, meaning we can increase the search rate by using more computers. We can do this by turning our system into a “worker” model, in which there is a continually growing queue of search blocks to process, and each worker machine asks for the next block to compute, computes it, and then stores the result in the database. There are some tricks required to ensure the workers don’t step on each other’s toes, but it’s a pretty standard computational model.
There’s also the possibility of analyzing our existing database to try to identify what properties of the top $ n$ values make their witness values so large. We could do this by re-computing the prime factorization of each of the numbers and squinting at it very hard. The benefit of doing this would ultimately be to design a new SearchStrategy that might find larger witness values faster than the superabundant enumeration. That approach also has the risk that, without a proof that the new search strategy is exhaustive, we might accidentally skip over the unique counterexample to the Riemann hypothesis!
And then, of course, there’s the business of a front-end and plotting. But I’m having a bit too much fun with the back end stuff to worry about that for now. Protest in the comments if you prefer I work on visualization instead.
Postscript: a false start
Here’s one thing I tried during debugging that turned out to be a dead end: the linux perf tool. It is way more detailed than I can understand, but it provides a means to let me know if the program is stuck in the OS kernel or whether it’s the applications that are slow. I ran the perf tool when the deployed application was in the “good performance” regime (early in its run). I saw something like this:
Samples: 59K of event 'cpu-clock:pppH', Event count (approx.): 119984000000
Overhead Command Shared Object Symbol
49.13% swapper [kernel.kallsyms] [k] native_safe_halt
8.04% python3 libpython3.7m.so.1.0 [.] _PyEval_EvalFrameDefault
1.35% python3 libpython3.7m.so.1.0 [.] _PyDict_LoadGlobal
0.86% python3 libc-2.28.so [.] realloc
0.86% python3 libpython3.7m.so.1.0 [.] 0x0000000000139736
0.77% python3 libpython3.7m.so.1.0 [.] PyTuple_New
0.74% python3 libpython3.7m.so.1.0 [.] PyType_IsSubtype
It says half the time is spent by something called “swapper” doing something called native_safe_halt, and this in kernel mode ([k]), i.e., run by the OS. The rest of the list is dominated by python3 and postgres doing stuff like _PyDict_LoadGlobal which I assume is useful Python work. When I look up native_safe_halt (finding an explanation is surprisingly hard), I learn that this indicates the system is doing nothing. So 49% of the time the CPU is idle. This fits with good behavior in our case, because each docker container gets one of the two CPUs on the host, and the postgres container is most often doing nothing while waiting for the search container to send it data. This also matches the CPU utilization on the EC2 dashboard. So everything appears in order.
I ran perf again after the application started slowing down, and I saw that native_safe_halt is at 95%. This tells me nothing new, sadly. I also tried running it during the timing test and saw about 40% usage of some symbols like __softirqentry_text_start and __lock_text_start. Google failed to help me understand what that was, so it was a dead end.
Want to respond? Send me an email, post a webmention, or find me elsewhere on the internet.