Recently I’ve been helping out with a linear algebra course organized by Tai-Danae Bradley and Jack Hidary, and one of the questions that came up a few times was, “why should programmers care about the concept of a linear combination?”
For those who don’t know, given vectors $ v_1, \dots, v_n$, a linear combination of the vectors is a choice of some coefficients $ a_i$ with which to weight the vectors in a sum $ v = \sum_{i=1}^n a_i v_i$.
I must admit, math books do a poor job of painting the concept as more than theoretical—perhaps linear combinations are only needed for proofs, while the real meat is in matrix multiplication and cross products. But no, linear combinations truly lie at the heart of many practical applications.
In some cases, the entire goal of an algorithm is to find a “useful” linear combination of a set of vectors. The vectors are the building blocks (often a vector space or subspace basis), and the set of linear combinations are the legal ways to combine the blocks. Simpler blocks admit easier and more efficient algorithms, but their linear combinations are less expressive. Hence, a tradeoff.
A concrete example is regression. Most people think of regression in terms of linear regression. You’re looking for a linear function like $ y = mx+b$ that approximates some data well. For multiple variables, you have, e.g., $ \mathbf{x} = (x_1, x_2, x_3)$ as a vector of input variables, and $ \mathbf{w} = (w_1, w_2, w_3)$ as a vector of weights, and the function is $ y = \mathbf{w}^T \mathbf{x} + b$.
To avoid the shift by $ b$ (which makes the function affine instead of purely linear; formulas of purely linear functions are easier to work with because the shift is like a pesky special case you have to constantly account for), authors often add a fake input variable $ x_0$ which is always fixed to 1, and relabel $ b$ as $ w_0$ to get $ y = \mathbf{w}^T \mathbf{x} = \sum_i w_i x_i$ as the final form. The optimization problem to solve becomes the following, where your data set to approximate is $ \{ \mathbf{x}_1, \dots, \mathbf{x}_k \}$.
$$\displaystyle \min_w \sum_{i=1}^k (y_i – \mathbf{w}^T \mathbf{x}_i)^2$$In this case, the function being learned—the output of the regression—doesn’t look like a linear combination. Technically it is, just not in an interesting way.
It becomes more obviously related to linear combinations when you try to model non-linearity. The idea is to define a class of functions called basis functions $ B = \{ f_1, \dots, f_m \mid f_i: \mathbb{R}^n \to \mathbb{R} \}$, and allow your approximation to be any linear combination of functions in $ B$, i.e., any function in the span of B.
$$\displaystyle \hat{f}(\mathbf{x}) = \sum_{i=1}^m w_i f_i(\mathbf{x})$$Again, instead of weighting each coordinate of the input vector with a $ w_i$, we’re weighting each basis function’s contribution (when given the whole input vector) to the output. If the basis functions were to output a single coordinate ($ f_i(\mathbf{x}) = x_i$), we would be back to linear regression.
Then the optimization problem is to choose the weights to minimize the error of the approximation.
$$\displaystyle \min_w \sum_{j=1}^k (y_j – \hat{f}(\mathbf{x}_j))^2$$As an example, let’s say that we wanted to do regression with a basis of quadratic polynomials. Our basis for three input variables might look like
$$\displaystyle \{ 1, x_1, x_2, x_3, x_1x_2, x_1x_3, x_2x_3, x_1^2, x_2^2, x_3^2 \}$$Any quadratic polynomial in three variables can be written as a linear combination of these basis functions. Also note that if we treat this as the basis of a vector space, then a vector is a tuple of 10 numbers—the ten coefficients in the polynomial. It’s the same as $ \mathbb{R}^{10}$, just with a different interpretation of what the vector’s entries mean. With that, we can see how we would compute dot products, projections, and other nice things, though they may not have quite the same geometric sensibility.
These are not the usual basis functions used for polynomial regression in practice (see the note at the end of this article), but we can already do some damage in writing regression algorithms.
A simple stochastic gradient descent
Although there is a closed form solution to many regression problems (including the quadratic regression problem, though with a slight twist), gradient descent is a simple enough solution to showcase how an optimization solver can find a useful linear combination. This code will be written in Python 3.9. It’s on Github.
First we start with some helpful type aliases
from typing import Callable, Tuple, List
Input = Tuple[float, float, float]
Coefficients = List[float]
Gradient = List[float]
Hypothesis = Callable[[Input], float]
Dataset = List[Tuple[Input, float]]
Then define a simple wrapper class for our basis functions
class QuadraticBasisPolynomials:
def __init__(self):
self.basis_functions = [
lambda x: 1,
lambda x: x[0],
lambda x: x[1],
lambda x: x[2],
lambda x: x[0] * x[1],
lambda x: x[0] * x[2],
lambda x: x[1] * x[2],
lambda x: x[0] * x[0],
lambda x: x[1] * x[1],
lambda x: x[2] * x[2],
]
def __getitem__(self, index):
return self.basis_functions[index]
def __len__(self):
return len(self.basis_functions)
def linear_combination(self, weights: Coefficients) -> Hypothesis:
def combined_function(x: Input) -> float:
return sum(
w * f(x)
for (w, f) in zip(weights, self.basis_functions)
)
return combined_function
basis = QuadraticBasisPolynomials()
The linear_combination function returns a function that computes the weighted sum of the basis functions. Now we can define the error on a dataset, as well as for a single point
def total_error(weights: Coefficients, data: Dataset) -> float:
hypothesis = basis.linear_combination(weights)
return sum(
(actual_output - hypothesis(example)) ** 2
for (example, actual_output) in data
)
def single_point_error(
weights: Coefficients, point: Tuple[Input, float]) -> float:
return point[1] - basis.linear_combination(weights)(point[0])
We can then define the gradient of the error function with respect to the weights and a single data point. Recall, the error function is defined as
$$\displaystyle E(\mathbf{w}) = \sum_{j=1}^k (y_j – \hat{f}(\mathbf{x}_j))^2$$where $ \hat{f}$ is a linear combination of basis functions
$$\hat{f}(\mathbf{x}_j) = \sum_{s=1}^n w_s f_s(\mathbf{x}_j)$$Since we’ll do stochastic gradient descent, the error formula is a bit simpler. We compute it not for the whole data set but only a single random point at a time. So the error is
$$\displaystyle E(\mathbf{w}) = (y_j – \hat{f}(\mathbf{x}_j))^2$$Then we compute the gradient with respect to the individual entries of $ \mathbf{w}$, using the chain rule and noting that the only term of the linear combination that has a nonzero contribution to the gradient for $ \frac{\partial E}{\partial w_i}$ is the term containing $ w_i$. This is one of the major benefits of using linear combinations: the gradient computation is easy.
$$\displaystyle \frac{\partial E}{\partial w_i} = -2 (y_j – \hat{f}(\mathbf{x}_j)) \frac{\partial \hat{f}}{\partial w_i}(\mathbf{x}_j) = -2 (y_j – \hat{f}(\mathbf{x}_j)) f_i(\mathbf{x}_j)$$Another advantage to being linear is that this formula is agnostic to the content of the underlying basis functions. This will hold so long as the weights don’t show up in the formula for the basis functions. As an exercise: try changing the implementation to use radial basis functions around each data point. (see the note at the end for why this would be problematic in real life)
def gradient(weights: Coefficients, data_point: Tuple[Input, float]) -> Gradient:
error = single_point_error(weights, data_point)
dE_dw = [0] * len(weights)
for i, w in enumerate(weights):
dE_dw[i] = -2 * error * basis[i](data_point[0])
return dE_dw
Finally, the gradient descent core with a debugging helper.
import random
def print_debug_info(step, grad_norm, error, progress):
print(f"{step}, {progress:.4f}, {error:.4f}, {grad_norm:.4f}")
def gradient_descent(
data: Dataset,
learning_rate: float,
tolerance: float,
training_callback = None,
) -> Hypothesis:
weights = [random.random() * 2 - 1 for i in range(len(basis))]
last_error = total_error(weights, data)
step = 0
progress = tolerance * 2
grad_norm = 1.0
if training_callback:
training_callback(step, 0.0, last_error, 0.0)
while abs(progress) > tolerance or grad_norm > tolerance:
grad = gradient(weights, random.choice(data))
grad_norm = sum(x**2 for x in grad)
for i in range(len(weights)):
weights[i] -= learning_rate * grad[i]
error = total_error(weights, data)
progress = error - last_error
last_error = error
step += 1
if training_callback:
training_callback(step, grad_norm, error, progress)
return basis.linear_combination(weights)
Next create some sample data and run the optimization
def example_quadratic_data(num_points: int):
def fn(x, y, z):
return 2 - 4*x*y + z + z**2
data = []
for i in range(num_points):
x, y, z = random.random(), random.random(), random.random()
data.append(((x, y, z), fn(x, y, z)))
return data
if __name__ == "__main__":
data = example_quadratic_data(30)
gradient_descent(
data,
learning_rate=0.01,
tolerance=1e-06,
training_callback=print_debug_info
)
Depending on the randomness, it may take a few thousand steps, but it typically converges to an error of < 1. Here’s the plot of error against gradient descent steps.
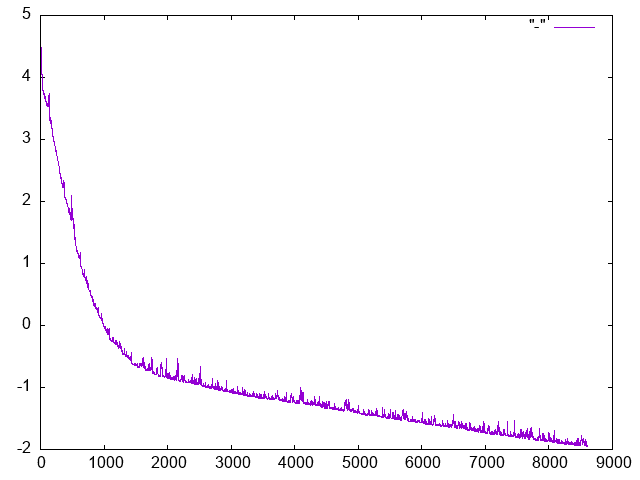
Gradient descent showing log(total error) vs number of steps, for the quadratic regression problem.
Kernels and Regularization
I’ll finish with explanations of the parentheticals above.
The real polynomial kernel. We chose a simple set of polynomial functions. This is closely related to the concept of a “kernel”, but the “real” polynomial kernel uses slightly different basis functions. It scales some of the basis functions by $ \sqrt{2}$. This is OK because a linear combination can compensate by using coefficients that are appropriately divided by $ \sqrt{2}$. But why would one want to do this? The answer boils down to a computational efficiency technique called the “Kernel trick.” In short, it allows you to compute the dot product between two linear combinations of vectors in this vector space without explicitly representing the vectors in the space to begin with. If your regression algorithm uses only dot products in its code (as is true of the closed form solution for regression), you get the benefits of nonlinear feature modeling without the cost of computing the features directly. There’s a lot more mathematical theory to discuss here (cf. Reproducing Kernel Hilbert Space) but I’ll have to leave it there for now.
What’s wrong with the radial basis function exercise? This exercise asked you to create a family of basis functions, one for each data point. The problem here is that having so many basis functions makes the linear combination space too expressive. The optimization will overfit the data. It’s like a lookup table: there’s one entry dedicated to each data point. New data points not in the training would be rarely handled well, since they aren’t in the “lookup table” the optimization algorithm found. To get around this, in practice one would add an extra term to the error corresponding to the L1 or L2 norm of the weight vector. This allows one to ensure that the total size of the weights is small, and in the L1 case that usually corresponds to most weights being zero, and only a few weights (the most important) being nonzero. The process of penalizing the “magnitude” of the linear combination is called regularization.
Want to respond? Send me an email, post a webmention, or find me elsewhere on the internet.