In the last article in the series, we migrated the passes we had written to use the tablegen code generation framework. That was a preface to using tablegen to define dialects.
In this article we’ll define a dialect that represents arithmetic on single-variable polynomials, with coefficients in $\mathbb{Z} / 2^{32} \mathbb{Z}$ (32-bit unsigned integers).
The code for this article is in this pull request, and as usual the commits are organized to be read in order.
Sketching out a design
The basic dialect will define a new polynomial type, and provide operations to define polynomials by specifying their coefficients from standard MLIR types, extract data about a polynomial to store the results in standard MLIR types, and to do arithmetic operations on polynomials.
There is quite a large surface area of design options when writing a dialect. This talk by Jeff Niu and Mehdi Amini gives some indication of how one might start to think about dialect design. But in brief, a polynomial dialect would fit into the “computation” bucket (a dialect to represent number crunching).
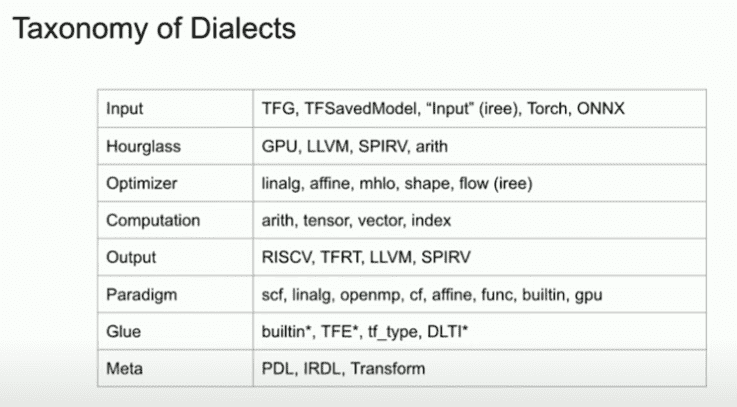
A slide from “MLIR Dialect Design and Composition for Front-End Compilers” (timestamped link), describing a taxonomy of dialects.
Another idea relevant to starting a dialect design is to ask how a dialect will enable easy optimizations. That is the Optimizer dialect class above. But since this tutorial series is focusing on the low-level, day to day, nitty gritty details of working with MLIR, we’re going to focus on getting some custom dialect defined, and then come back to what makes a good dialect design later.
An empty dialect
We’ll start by defining an empty dialect and just look at the tablegen-generated code, which is done in this commit. The tablegen file looks like
include "mlir/IR/DialectBase.td"
def Poly_Dialect : Dialect {
let name = "poly";
let summary = "A dialect for polynomial math";
let description = [{
The poly dialect defines types and operations for single-variable
polynomials over integers.
}];
let cppNamespace = "::mlir::tutorial::poly";
}
It is almost indistinguishable from the tablegen for a Pass, except for the Dialect base class. The build rule has different flags too.
gentbl_cc_library(
name = "dialect_inc_gen",
tbl_outs = [
(["-gen-dialect-decls"], "PolyDialect.h.inc"),
(["-gen-dialect-defs"], "PolyDialect.cpp.inc"),
],
tblgen = "@llvm-project//mlir:mlir-tblgen",
td_file = "PolyDialect.td",
deps = [
"@llvm-project//mlir:OpBaseTdFiles",
],
)
Unlike the Pass codegen, here the dialect has us specify a codegen’ed header and implementation file, which are short enough to include directly in the article:
// bazel-bin/lib/Dialect/Poly/PolyDialect.h.inc
namespace mlir {
namespace tutorial {
class PolyDialect : public ::mlir::Dialect {
explicit PolyDialect(::mlir::MLIRContext *context);
void initialize();
friend class ::mlir::MLIRContext;
public:
~PolyDialect() override;
static constexpr ::llvm::StringLiteral getDialectNamespace() {
return ::llvm::StringLiteral("poly");
}
};
} // namespace tutorial
} // namespace mlir
MLIR_DECLARE_EXPLICIT_TYPE_ID(::mlir::tutorial::PolyDialect)
And the cpp:
// bazel-bin/lib/Dialect/Poly/PolyDialect.cpp.inc
MLIR_DEFINE_EXPLICIT_TYPE_ID(::mlir::tutorial::PolyDialect)
namespace mlir {
namespace tutorial {
PolyDialect::PolyDialect(::mlir::MLIRContext *context)
: ::mlir::Dialect(getDialectNamespace(), context, ::mlir::TypeID::get<PolyDialect>()) {
initialize();
}
PolyDialect::~PolyDialect() = default;
} // namespace tutorial
} // namespace mlir
Basically, they are empty containers that will hold the types and ops that we define next.
In this commit we register the dialect with the tutorial-opt main program, which is handled by a single API call. Now the dialect shows up in the help text of the tutorial-opt binary, though nothing else is there because we have no passes associated with it.
$ bazel run tools:tutorial-opt -- --help
Available Dialects: ..., pdl_interp, poly, quant, ...
Adding a trivial type
Next we’ll define a poly.poly type with no semantics, and in the next section we’ll focus on the semantics.
This commit defines a simple test that ensures we can parse and print our new type.
// RUN: tutorial-opt %s
module {
func.func @main(%arg0: !poly.poly) -> !poly.poly {
return %arg0 : !poly.poly
}
}
Note that the exclamation mark ! sigil prefix is required for out-of-tree MLIR types.
Next, in this commit we add the tablegen for the poly type. The tablegen looks like
include "PolyDialect.td"
include "mlir/IR/AttrTypeBase.td"
// A base class for all types in this dialect
class Poly_Type<string name, string typeMnemonic> : TypeDef<Poly_Dialect, name> {
let mnemonic = typeMnemonic;
}
def Poly : Poly_Type<"Polynomial", "poly"> {
let summary = "A polynomial with i32 coefficients";
let description = [{
A type for polynomials with integer coefficients in a single-variable polynomial ring.
}];
}
This is effectively a boilerplate shell since nothing here is specific to polynomial arithmetic. But it shows a few new things about tablegen worth mentioning.
First and most trivially, tablegen has include statements so that you can split definitions across files. I like to put each conceptual type of thing in its own tablegen file (types, ops, attributes, etc.), but conventions differ across projects.
Second, a common pattern when defining types (and ops) is to have a base class for each dialect that all concrete type definitions inherit from. This shows first of all that there is a difference between class and def in tablegen. def defines actual types, where by “actual” I mean it generates C++ code, whereas class is only an inheritance base and disappears after tablegen is done. Think of class as allowing us to refactor out common shared code among type definitions in one file. I make a stink of this because I have mixed up class and def many times and been confused by the error messages and generated code. For example, if you change the class to a def above, you’ll see the following unhelpful error message.
lib/Dialect/Poly/PolyTypes.td:8:5: error: Expected a class name, got 'Poly_Type'
def Poly_Type<string name, string typeMnemonic> : TypeDef<Poly_Dialect, name> {
Moreover, TypeDef itself is a class that takes as template arguments the dialect the type should belong to and a name field (related to the type’s eventual C++ class name), and results in Tablegen associating the generated C++ classes with the same namespace as we told the dialect to use, among other things.
Third, the new field is the mnemonic declaration. This determines the name of the type in the textual representation of the IR.
The generated code again has separate .h.inc and .cpp.inc files:
// PolyTypes.h.inc
#ifdef GET_TYPEDEF_CLASSES
#undef GET_TYPEDEF_CLASSES
namespace mlir {
class AsmParser;
class AsmPrinter;
} // namespace mlir
namespace mlir {
namespace tutorial {
namespace poly {
class PolynomialType;
class PolynomialType : public ::mlir::Type::TypeBase<PolynomialType, ::mlir::Type, ::mlir::TypeStorage> {
public:
using Base::Base;
static constexpr ::llvm::StringLiteral getMnemonic() {
return {"poly"};
}
};
} // namespace poly
} // namespace tutorial
} // namespace mlir
MLIR_DECLARE_EXPLICIT_TYPE_ID(::mlir::tutorial::poly::PolynomialType)
#endif // GET_TYPEDEF_CLASSES
// PolyTypes.cpp.inc
#ifdef GET_TYPEDEF_LIST
#undef GET_TYPEDEF_LIST
::mlir::tutorial::poly::PolynomialType
#endif // GET_TYPEDEF_LIST
#ifdef GET_TYPEDEF_CLASSES
#undef GET_TYPEDEF_CLASSES
static ::mlir::OptionalParseResult generatedTypeParser(::mlir::AsmParser &parser, ::llvm::StringRef *mnemonic, ::mlir::Type &value) {
return ::mlir::AsmParser::KeywordSwitch<::mlir::OptionalParseResult>(parser)
.Case(::mlir::tutorial::poly::PolynomialType::getMnemonic(), [&](llvm::StringRef, llvm::SMLoc) {
value = ::mlir::tutorial::poly::PolynomialType::get(parser.getContext());
return ::mlir::success(!!value);
})
.Default([&](llvm::StringRef keyword, llvm::SMLoc) {
*mnemonic = keyword;
return std::nullopt;
});
}
static ::mlir::LogicalResult generatedTypePrinter(::mlir::Type def, ::mlir::AsmPrinter &printer) {
return ::llvm::TypeSwitch<::mlir::Type, ::mlir::LogicalResult>(def)
.Case<::mlir::tutorial::poly::PolynomialType>([&](auto t) {
printer << ::mlir::tutorial::poly::PolynomialType::getMnemonic();
return ::mlir::success();
})
.Default([](auto) { return ::mlir::failure(); });
}
namespace mlir {
namespace tutorial {
namespace poly {
} // namespace poly
} // namespace tutorial
} // namespace mlir
MLIR_DEFINE_EXPLICIT_TYPE_ID(::mlir::tutorial::poly::PolynomialType)
#endif // GET_TYPEDEF_CLASSES
The name PolynomialType is generated by adding Type to the "Polynomial" template argument we passed in the tablegen file. The name of the def itself is used to refer to the class elsewhere in tablegen files, and the two can be different.
One thing to pay attention to here is that tablegen is attempting to generate a type parser and printer for us. But it’s not usable yet—we’ll come back to this. If you build at this commit you’ll see a compiler warning like generatedTypePrinter defined but not used and a hard failure if you try running the test.
A second thing to notice is that it uses the header-guards-as-function-arguments style again, here to separate the cpp file into two include-guarded sections, one that just has a list of the types defined, and the other that has implementations of functions. The first one, GET_TYPEDEF_LIST is curious because it just includes a comma-separated list of class names. This is because the PolyDialect.cpp from this commit is responsible for registering the types with the dialect, and that happens by using this include to add the C++ class names for the types as template arguments in the Dialect’s initialization function.
// PolyDialect.cpp
#include "lib/Dialect/Poly/PolyDialect.h"
#include "lib/Dialect/Poly/PolyTypes.h"
#include "mlir/include/mlir/IR/Builders.h"
#include "llvm/include/llvm/ADT/TypeSwitch.h"
#include "lib/Dialect/Poly/PolyDialect.cpp.inc"
#define GET_TYPEDEF_CLASSES
#include "lib/Dialect/Poly/PolyTypes.cpp.inc"
namespace mlir {
namespace tutorial {
namespace poly {
void PolyDialect::initialize() {
addTypes<
#define GET_TYPEDEF_LIST
#include "lib/Dialect/Poly/PolyTypes.cpp.inc"
>();
}
} // namespace poly
} // namespace tutorial
} // namespace mlir
We’ll do the same registration dance for ops, attributes, etc., later.
The expected way to set up the C++ interface to the tablegen files is:
- Create a header file
PolyTypes.hwhich is the only file allowed to includePolyTypes.h.inc, - Include
PolyTypes.cpp.incinsidePolyDialect.cppwith any additional#includes needed for the auto-generated implementations inPolyTypes.cpp.inc. In our case, the default parser/printer uses the type switch function fromllvm/include/llvm/ADT/TypeSwitch.h. - If needed, add a
PolyTypes.cppwith any additional implementations needed for functions declared by tablegen that can’t be automatically generated.
I don’t think I’ve found the best arrangement of these files and build targets yet. What I really want is to have each header with a corresponding .h.inc, a corresponding .cpp file that includes the relevant .cpp.inc, and to connect them all with PolyDialect.cpp. However, PolyDialect::initialize does some introspection on the classes declared in PolyTypes.h.inc to ensure they’re valid (specifically looking for details of Storage types like is_trivially_destructible, which are generated for us in the next section), and that requires the implementations to exist in the same compilation unit (I believe). From what I’ve read of other projects, people just tend to cram things into the same cpp files, leading to multi-thousand line implementation files, which I dislike.
As a final note, the build file uses a new rule called td_files to group all the tablegen files into one build target.
The last ingredient required to get this to compile and run is to make the type parser and printer usable. Thankfully it’s one line: adding let useDefaultTypePrinterParser = 1; to the dialect tablegen (see this commit). This adds the following declarations to PolyDialect.h.inc, and modifies the generated implementations to be member functions on PolyDialect.
/// Parse a type registered to this dialect.
::mlir::Type parseType(::mlir::DialectAsmParser &parser) const override;
/// Print a type registered to this dialect.
void printType(::mlir::Type type,
::mlir::DialectAsmPrinter &os) const override;
Adding a poly type parameter
When designing the poly type, we have to think about what we want to express, and how the type will be lowered to types in lower level dialects. For the sake of this tutorial we’ll restrict to single-variable polynomials, so the indeterminate can be arbitrary and implicit (we don’t need to keep track of the variable name x or y or t in the IR).
The next question is the polynomial analogue of integer bit width: degree. The difficulty here is that tracking the exact degree of a polynomial is impossible in general. The degree of a sum of two polynomials depends on the coefficient values (the highest degree terms may cancel), which may not be known statically because they are read from an external source at runtime. So at best we could track an upper bound on the degree.
The simplest approach is to require a polynomial type to declare its “degree upper bound” statically, and then define “overflow” semantics just like integers have. A natural option is to implicitly treat polynomials as members of a ring $R[x]/ (x^D-1)$, where $D$ is the degree upper bound and $R$ is the ring of 32-bit unsigned integers. In less mathematical terms, this means that whenever a term $x^n$ in a polynomial would exceed degree $D \leq n$, we would replace $x^n$ with $x^{n \mod D}$, which is the same thing as “declaring” $x^D=1$ and reducing polynomials via that substitution until all terms have degree less than $D$.
This simple approach has the benefit of making the dialect design easy: all binary polynomial ops have the same input and output type, and lowering a poly type requires replacing poly.poly<D> with a tensor of D coefficients. Since the shapes are static and most polynomials would have the same bound, it’s probably the most performant option. The downsides are that now the programmer has to worry about overflow semantics, and if you want polynomials of larger degree you have to insert bookkeeping operations to extend the degree bound.
On the other hand, we could allow a poly to have a growing degree. So that, e.g., a poly.mul operation with two poly.poly<7> input polynomials would have a poly.poly<14> as output. This would require more work in the dialect definition to ensure the IR is valid, and the lowering would be more complex in that you’d have to manage tensors of different sizes. It would probably also have an impact on performance, since there would be more memory allocations and copying involved (but maybe the compiler could be smart enough to avoid that).
I would like to do both so as to show how these differences materialize in lowerings and optimization passes. But for now I will start with the one that I think is easier: wrapping overflow semantics.
To make that work, we need to add an attribute to our polynomial type representing its degree upper bound. The official docs on how to do this are here.
This is where tablegen starts to be quite useful, because the changes only require two lines added to the type definition’s tablegen.
let parameters = (ins "int":$degreeBound);
let assemblyFormat = "`<` $degreeBound `>`";
The first line associates each instance of the type with an integer parameter (the "int" can be any string containing a literal C++ type), and a name $degreeBound that is used both for the generated C++ and to refer to it elsewhere in the tablegen file.
The second line is required because now that a poly type has this associated data, we need to be able to print it to and parse it from the textual IR representation. This simplest option is to let tablegen auto-generate the parser and printer for us, but we could have also used the line let hasCustomAssemblyFormat = 1; which would generate some headers that it expects us to fill in the implementation for. In the syntax of that line, tokens in backticks are literally printed/parsed.
After adding these two lines in this commit, the generated code gets quite a bit more complicated. Here’s the entirety of both files. Some things to note:
PolynomialTypegets a newint getDegreeBound()method, as well as a staticget(MLIRContext, int)factory method.- The parser and printer are upgraded to the new format.
- There is a new class called
PolynomialTypeStoragethat holds the int parameter and is hidden in an innerdetailnamespace.
The storage class is autogenerated for us now because integers have simple construction/destruction semantics. If we had a more complicated argument like an array that needed allocation, we’d have to implement special classes to define those semantics. And at the most extreme end, if we had a fully custom type parameter, we’d have to implement a storage class manually, implement things like hash_code, and register it with the dialect. For the curious, I had to do this in heir/pull/74 to implement a custom Polynomial type parameter.
The same commit updates the syntax test to include the type parameter.
Adding some simple operations
Moving a bit faster now, we want to add some polynomial operations. This commit adds a polynomial addition op. The tablegen:
include "PolyDialect.td"
include "PolyTypes.td"
def Poly_AddOp : Op<Poly_Dialect, "add"> {
let summary = "Addition operation between polynomials.";
let arguments = (ins Polynomial:$lhs, Polynomial:$rhs);
let results = (outs Polynomial:$output);
let assemblyFormat = "$lhs `,` $rhs attr-dict `:` `(` type($lhs) `,` type($rhs) `)` `->` type($output)";
}
It looks very similar to a type, but the base class is Op, the arguments correspond to the operation’s inputs, and the assembly format is more complicated. We’ll enhance it in a future article, but the reason is that without inserting some special hooks, tablegen isn’t able to generate a parser that can infer what the types of the inputs and outputs should be when constructing it from the textual representation. [Aside: I feel like it should be able to with the simple example above, but for whatever reason the MLIR devs appear to have made auto-generated type inference opt-in via the trait infrastructure, see next article.]
Still, we can add a test and it passes
// CHECK-LABEL: test_add_syntax
func.func @test_add_syntax(%arg0: !poly.poly<10>, %arg1: !poly.poly<10>) -> !poly.poly<10> {
// CHECK: poly.add
%0 = poly.add %arg0, %arg1 : (!poly.poly<10>, !poly.poly<10>) -> !poly.poly<10>
return %0 : !poly.poly<10>
}
The generated C++ has quite a bit more going on. Here’s the full generated code. Mainly the generated header defines AddOp which has getters for the arguments and results, “mutable” getters for modfying the op in place, parse/print, and generated builder methods. It also defines an AddOpAdaptor class which is used during lowering. The cpp file contains mostly rote implementations of these, converting from a generic internal representation to specific types and named objects that client code would use.
Next, in this commit I added a sub and mul operation, with a slight refactoring to make a base tablegen class for a binary operation.
Next, in this commit I added a from_tensor operation that converts a list of coefficients to a polynomial, and an eval op that evaluates a polynomial at a given input value.
In the next few articles we’ll expand on this dialect’s capabilities. First, we’ll study what other “batteries” we can include in the dialect itself, and how we can run optimizations on poly programs. Then we’ll study the nuances of lowering poly to existing MLIR dialects, and eventually through to LLVM and then machine code.
Want to respond? Send me an email, post a webmention, or find me elsewhere on the internet.